数据库:sql基本命令介绍
存储过程
Intro
自定义的数据库API,一系列sql语句的集合(这两个概念非常重要)
查看数据库中的所有存储过程/具体信息查看:
1 | show procedure status; |
删除存储过程:
1 | drop procedure if exists proc_name; |
调用存储过程:
1 | call proc_name(); |
存储过程中的变量:
1 | declare a, b, c int default 5;(变量名,类型,默认值) |
Example
注意,在begin…end之间可以执行多条命令,另外注意delimiter的格式
1 | delimiter // |
事件机制
时间调度器event schduler和事件event的异同,请理清
查看是否开启了event schedule的方法
1 | SHOW VARIABLES LIKE ‘event_scheduler'; |
Update
1 | alter event event_name |
close/open/delete event
1 | # 关闭 |
Show
1 | select * from mysql.event; |
Call
1 | create event |
Example
间隔事件内判断某一个表中所有数据的时间差是否大于60秒:
1 | create event |
函数机制
Example
获取随机字符串:
1 | drop function if exists rand_string; |
调用时:
1 | select rand_string(6); |
如果某一个值长度不为12:
1 | update radcheck set value=rand_string(12) where username='zheng' and loginenable=FALSE and length(value) !=12; |
布尔类型
boolean(TRUE,FALSE)两种求值
通配符
like
- 字符%: 表示任意多个字符,匹配任意长度
- 包含: like ‘%str%’ and like ‘%ptr%’
- 不包含: not like ‘%str%’
运行状态
线程或者任务
命令:show processlist;
说明:每一个用户只能看到自己所属的运行线程,除非超级用户
输出说明: id-标识,command(sleep-休眠,query-查询,connect-连接), time-该命令该状态持续的时间,state-语句执行中的一个状态,info-sql语句
state
mysql运行命令过程中会有多个状态,详细的显示了命令执行过程或者阶段、碰到的问题等。
- checking table: 检查数据库
- closing table: 将table修改数据写入到DB,同时关闭table,该操作是一个快速操作,否则磁盘满或者其他问题
- copying to tmp table on disk: 临时结果集过大,将临时表数据从内容拷贝到磁盘
- creating tmp table: 创建临时表以存放查询结果
- deleting from main table: 多表删除,刚刚删除第一个表
- deleting from reference table: 正在删除其他表
- flushing table: 等待其他线程关闭数据表
- waiting for table: 表结构已经被更改,需要重新获取table结构
- connect out: 从服务器正在连接主服务器
- killed: 正在被杀死
- locked: 被其他查询锁住
- system lock: 正在等待一个外部锁
- upgrading lock:
- User lock: 等待GET_LOCK()
- sending data: 正在处理select查询记录,并且正在将结果发送到客户端
- sorting for group: 正在为GROUP BY排序
- sorting for order
- Opening tables: 除非被其他因素干扰(alter, locked),否则打开速度很快
- Reopen table:
- Sleeping: 正在等待客户端发送新的请求,一旦你使用任何客户端连接时都会有该线程任务
嵌套查询
查询两个表中某一个字段的值相同的行信息
select * from A where exists(select * from B where A.a = B.a);
查询A中某一个字段不等于B的所有行信息:
1 | select distinct modulename from ossweb_svrinfo where not exists( |
事务处理
自动提交事务
命令:set autocommit=1 或者 start transcation–>sql命令–>commit
命名标准
表名或者库名
禁用’-‘(中划线)
密码
- 禁用’/‘,该字符在mysql中是一个特殊字符
- 在使用mysql命令行登录时,尽量不要输入或者显示明文,当然,调试的时候建议使用
外键
疑惑:
为何大学里面所有的数据库项目都涉及到主外键的设计,但是一到互联网公司中,完全不见主外键的设置??
业务应用场景
互联网行业: 用户量大、并发度高、数据库服务器容易成为性能瓶颈(尤其是IO能力)、不能轻易的水平扩展
传统行业: 软件应用人数有限或者可控,数据量不是非常大
使用: 在互联网行业中,将数据的一致性控制全部放在事务(transcation)中,让应用服务器承担此项压力,从而保证引用服务器能够轻松的水平伸缩。
性能原因
- 数据库本身维持了一份主外键的内部管理
- 外键等于将数据的一致性事务实现全部交由数据库引用服务器来完成;
- 外键会消耗正常的add/del/insert/update的消耗;
- 容易出现死锁
优势
- 降低开发成本,借助数据库产品的触发器等等来实现关联表之间的数据一致性问题(大学里面的oracle)
- 开发人员和数据库设计人员的分工
延伸理解
这就是为什么在前段页面,尽量少的使用复杂数据库语言,尽量少的在数据库上进行函数调用等操作团战可以输、提莫必须死—>应用服务器可以挂(一部分),但是引用服务器不能挂.
unique/primary/null
unique或者primary的字段必须长度尽可能小,例如varchar(256)的name字段就不能作为unique字段
OLTP, OLAP
Intro
Reference: OLTP, OLAP比较
Function: 数据库系统分为两种类型: 面向前台应用-重吞吐, 高并发; 重计算-大数据集统计分析.
OLTP(联机事务处理)
Function: on-line transaction processing, 传统关系型数据库的应用, 一般为: 基本的, 日常的事务处理
Feature: 强调内存效率, 强调绑定变量, 强调并发操作. 事务性非常高的系统, 用于高可用的在线系统, 以小的事务以及小的查询为主.
Performance: 每秒执行的transaction数量, Execute SQL数量为判断依据.
Application: 电子商务系统, 银行, 证券.
OLAP(联机分析处理)
Function: On-line analytical processing, 数据库仓库系统的应用, 支持复杂的分析操作, 侧重决策支持, 提供直观易懂的查询结果
Feature: 强调数据分析, 强制 SQL 执行市场, 强调磁盘I/O, 强调分区
Referenc: OLAP分析
Comparison
OLTP: 事务, 但是不易扩容
OLAP: 非事务
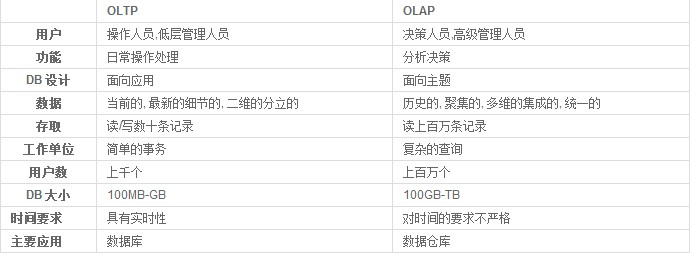
Choose DB
Data Size:
- 百万级别数据: 无论 OLTP, OLAP, 一般都选择 MYSQL
- 过亿级别数据: 测试 OLTP 的可以继续选择 MYSQL, 测试 OLAP 的需要分场景
Choose OLAP:
- 实时计算场景: Storm
- 批处理计算场景: 数据挖掘, 数据分析, hadoop
- 实时查询场景: solr/elasticsearch
 alipay
alipay








