python多重继承
站内链接:
Defined
MRO: method resolution order, 方法或类解析顺序,用于确定类中方法, 属性的查找规则, 查找顺序.
LEGB: 作用域的查找逻辑, 其查找链条为Local-->Enclosing function locals-->Globls-->Built-in, 关于作用域, 命名空间, 闭包等相关知识点见站内连接作用域和命名空间文章说明.
为了下面素有章节的说明更加清晰化, 我们在这里先预定设置一个 python 继承的实例(1.1 例), 这是一个多继承:
1 | class A: |
Rule
human 规则
- 经典类
- 从左向右(多继承类中从左到右),深度优先遍历
- 遍历中出现重复的类函数,保留
首个 - 上述实例的打印顺序: D, B, A, C, 所以
D().show()的输出为:A
- 新式类(python2 中, A 继承 object)
- 从左向右(多继承类中从左到右),深度优先遍历
- 遍历中出现重复的类或函数,保留
最后一个 D, B, A, object, C, A, object, 重复类仅仅保留最后一个, 故最后顺序:D, B, C, A, object- 上述实例的打印,
D().show()输出为:C - 新式类可通过
A.__mro__查看 mro 值信息
但是该逻辑在复杂的继承关系中会出现一些问题, 例如(2.1 例):
1 | class A: |
对于 X 来说, 其搜索顺序: B, A, object, C, 对于 Y 来说明, 其搜索顺序为: C, A, object, B, 此时会发现 X, Y 两者的搜搜顺序是相反的, 从而产生问题, 另外还违反了继承关系的单调性原则.
A MRO is monotonic when the following is true: if C1 precedes C2 in the linearization of C, then C1 precedes C2 in the linearization of any subclass of C. Otherwise, the innocuous operation of deriving a new class could change the resolution order of methods, potentially introducing very subtle bugs.
单调性原则: 子类不能改变基类的方法搜索顺序.
- C3 方法(python2.3 之后)
- 继承新式类的查找逻辑
- 禁止二义性的继承代码, 例如 2.1 例中如果出现
class C(A, B)则会抛出异常
1 | TypeError: Cannot create a consistent method resolution |
数学推导规则
- 将类 C 的线性化称呼为 MRO, 记为
L[C] == [C1, C2, ..., Cn],其中 C1 就是 当前最底部的类,称为头,其余称为尾. - 假定 C 类的继承关系为:
1 | class C(B1, B2, ..., Bn): |
即B1,B2, ..., Bn为倒数第二层级
根据推导得出:
1 | a) L[object] = [object] |
其中 merge 语法:
1 | 1. 检查首个元素的头部,记为 H,即为深度优先遍历最早的一个元素 H |
推导公式:
1 | L[A] = [A] + merge(L[X], L[Y], [X], [Y]) |
对于如下的继承关系: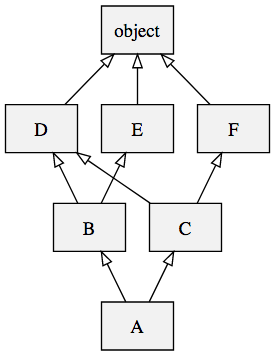
其完整的推导公式:
1 | L[object] = [object] |
例子
Mixin
mixin: 混入, 一种编程模式的用法, 每一个 mixin 都是某一个功能单元的类, 每一个 mixin 可以插入到任意子类继承链中, 多个 mixin 可以组合到一个子类的继承中, 其就是一个个模块化的单元插件, 根据程序自由组合.
使用场景: 一个守护轮询进程不断的消费 MQ 中的消息, 关于消息的解析, 消息的基本格式化都可以在回调基类中按照通用格式完成,
但是这并不能适用于所有的数据, 如果这些数据还有非常多的特征, 比如类型, 颜色, 大小等等一大堆不同的特性, 那么对于不同的特征肯定需要不同的函数来解析. 按照正常逻辑进行编写会导致各个数据类型的子类出现重复代码, 子类非常冗余, 那么此时 mixxin 就能非常方便的处理该使用场景.
1 | class BaseData: |
通过这种即插即用自由实现需要的功能
拆分实现逻辑
在某次应用场景中, 底层基类实现逻辑代码非常多, 并且代码分为两种操作类型: 数据库对象操作, 字符串序列化操作, 并且后者需要同其他微服务一起进行数据的请求和数据的解析操作, 这是为了以后代码迁移更加方便, 故而将这两部分代码拆分开来, 其整体逻辑如下:
1 | class BaseHandler: |
通过上述的类继承关系, 将一个非常大的OracleDatabaseHandler给强行分开, 并且实现了处理类型的模块化, 只不过这里不应该叫做 mixin, 因为 mixin 中的函数一般都是独立的, 逻辑自洽的, 但是这里 BaseMixin, OracleMixin 会用到 BaseHandler 中创建的很多数据, 此时可能会有疑惑, 这里仅仅介绍另外一种多继承可能的用法.
另外, 此时对于OracleDatabaseHandler, 其查找顺序: ODH, DH, BH, OM, BM, 所以OracleDatabaseHandler().log_info()实际上调用的是基类的实现代码, 当然, 这也可以当成是多继承乱用的反例.
Namespace and Field
namespace–”命名–对象的映射”,在 Python 中使用 dictionary 来实现
field–直接能够访问到的”namespace”
属性名查找顺序
“属性”—任何”.”后面的名称
类:实例属性–>类属性–>父类属性(MRO)
模块:模块作用域–>导入包作用域
namespace
namespace 们在”不同的时刻”创建,存在着不同的声明周期.
builtins: 内置名称的命名空间在 Python interpreter 启动时创建,模块名为 builtins
module: 模块的全局命名空间在模块定义被导入读取时创建,一般伴随着 Python interpreter 的整个声明周期,被顶级解释器调用的属性在** main**模块中
functions: 函数的命名空间在函数创建时定义,返回或者抛出异常时销毁
field
field–仅仅是一个结构上的区域范围,它在结构上决定作用区域.
permissions: 对于某一个 namespace,至少三个嵌套的 field 可以直接访问:
- 最内层的作用域,locals
- 全局变量 globals(函数名, 全局变量)
- 最外层, builtins 名称
update
- 赋值并没有拷贝数据,仅仅绑定名字到对象上
- del X 仅仅是将变量 X 从当前作用域移除绑定
- import 就是将模块和函数绑定到当前作用域
nonlocal 和 global
global: 指示全局作用域中的变量可以绑定到当前作用域(引用),如果全局命名空间在一开始不存在变量 X, 则赋值之后就会存在.
nonlocal: 指示在一个闭合的作用域中的变量可以在此绑定
 alipay
alipay