站内链接:
架构 SLA SLA(Service Level Agreement)是一种服务级别协议,用于定义服务提供商与客户之间的服务水平要求和责任。SLA 通常包含以下内容:
服务范围:明确描述所提供的服务的具体范围和内容,包括功能、性能、可用性等方面的要求。
响应时间:规定在客户提出请求后,服务提供商需要在多长时间内做出响应。
解决时间:规定在出现问题或故障时,服务提供商需要在多长时间内解决问题或恢复服务。
可用性要求:定义服务的可用性要求,例如系统正常运行时间的百分比或故障允许的最大时间。
故障处理:规定在服务中出现故障时,服务提供商需要采取的具体措施和处理流程。
客户支持:明确规定服务提供商为客户提供的支持方式、时间和响应要求。
问题来了,SLA 是怎么量化的?其实就是按照停服时间算的。怎么算的?举个例子:
1 年 = 365 天 = 8760 小时 99.9 停服时间:8760 * 0.1% = 8760 * 0.001 = 8.76 小时 99.99 停服时间:8760 * 0.0001 = 0.876 小时 = 52.6 分钟 99.999 停服时间:8760 * 0.00001 = 0.0876 小时 = 5.26 分钟
也就是说,SLA 协议指明提供 5 个 9 的高可用服务,那就要保证一年的时间内对象存储的停服时间少于 5.26 分钟,如果超过这个时间,就算违背了 SLA 协议。
HA 自动故障转移有点类似 Redis 的哨兵机制,该功能也是为何Replica Set会替换主从模式的最主要原因。 当主节点出现故障时,副本集会进行故障转移,余下节点会进行新的主节点选举。选举出的主节点继续提供服务,原故障的主节点修复后,自动重新加入副本集作为从节点。
选举时间: 主节点故障后(electionTimeoutMillis 内无法和其他节点通行,默认 10s),在满足选举要求的情况下,在 leaseTime 内完成节点选举 (默认 30s)。
选举规则: 参与选举的节点数量要大于副本集中节点总数的一半,选举过程中,每个从节点都会投票给自己或其他从节点,选择得票最多的节点作为新的主节点
选举读写: 副本集在选举成功前是无法处理写操作的。如果读请求被配置运行在 从节点 上,则当主节点下线时,副本集可以继续处理这些请求。
数据同步:选举出的新主节点会开始与其他从节点同步数据。它会将自己的操作日志(Oplog)发送给其他从节点,让它们更新自己的数据,以达到数据一致性。
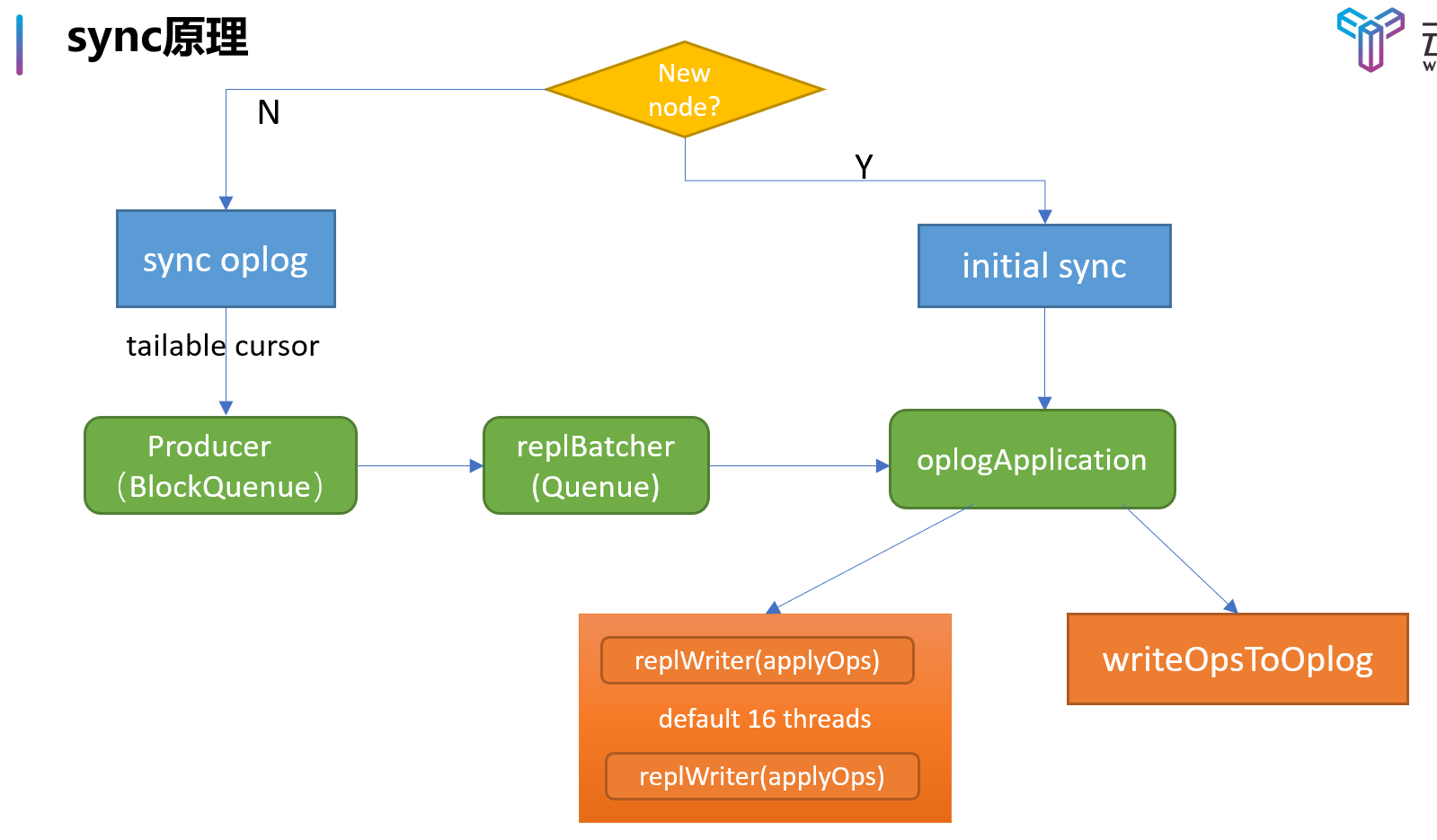
复制原理 Mongo 的主从复制原理分为两个阶段:
Initial Sync 阶段:此阶段是备端刚刚加入副本集中,此时通过 init sync 同步主端的全量数据,这个流程就是获取到所有 DB 的集合并创建相应的索引信息
Replication 阶段:此阶段才是真正的正常状态下的主从复制
在 Replication 阶段,备端从结束时间点建立tailable cursor,不断的从同步源拉取 oplog 并重放应用到自身,这个过程并不是由一个线程来完成的,mongodb 为了提升同步效率,将拉取 oplog 以及重放 oplog 分到了不同的线程来执行。
producer thread:这个线程不断的从同步源上拉取 oplog,并加入到一个 BlockQueue 的队列里保存着,BlockQueue 最大存储 240MB 的 oplog 数据,当超过这个阈值时,就必须等到 oplog 被 replBatcher 消费掉才能继续拉取。
replBatcher thread:这个线程负责逐个从 producer thread 的队列里取出 oplog,并放到自己维护的队列里,这个队列最多允许 5000 个元素,并且元素总大小不超过 512MB,当队列满了时,就需要等待 oplogApplication 消费掉
oplogApplication 会取出 replBatch thread 当前队列的所有元素,并将元素根据 docId(如果存储引擎不支持文档锁,则根据集合名称)分散到不同的 replWriter 线程,replWriter 线程将所有的 oplog 应用到自身;等待所有 oplog 都应用完毕,oplogApplication 线程将所有的 oplog 顺序写入到 local.oplog.rs 集合。
这个多线程合作方式有点类似 MySQL 的主从复制原理,整个主从复制过程如下:
Master-Slave 模式 该策略和 MySQL 的热备策略是非常相似的,Master-Slave 是一种冗余策略,用于实现高可用性和数据冗余。该策略基于主从复制的原理,将数据从主节点复制到一个或多个从节点。其提供了如下功能:
数据冗余:数据被复制到多个从节点,即使主节点发生故障,数据仍然可用。
读写分离:读操作可以在从节点上进行,减轻主节点的负载,提高系统的读取性能
扩展性(一定程度):通过增加从节点来扩展系统的读取能力。
但是,它的缺点也类似 MySQL 的主从架构:
数据全量冗余:对于主从的硬件性能要求非常大,这点对于非分布式系统都是存在,只能通过分布式系统或者分库分表来提高。
写操作只能在主节点上进行:在 Master-Slave 模式下,所有的写操作都需要发送到主节点上进行处理,从节点只能用于读取操作。这可能会导致主节点成为性能瓶颈,特别是在高写入负载下
故障切换可能引起服务中断:当主节点发生故障时,需要进行故障切换,将一个从节点升级为新的主节点。在这个过程中,可能会发生一段时间的服务中断,因为切换需要重新选举新的主节点和重新连接客户端。
配置和管理复杂性:在 Master-Slave 模式下,需要正确配置和管理主节点和从节点之间的复制关系。这包括处理节点的添加、删除、故障恢复等操作,需要额外的配置和管理工作。
读写一致性问题:由于从节点的数据副本存在一定的延迟,可能会导致读写一致性的问题。即在写入后立即进行读取操作时,可能会读取到旧的数据。
MongoDB 3.6 起已不推荐使用主从模式,自 MongoDB 3.2 起,分片群集组件已弃用主从复制。因为 Master-Slave 其中 Master 宕机后不能自动恢复,只能靠人为操作,可靠性也差,操作不当就存在丢数据的风险。
另外,该模式在 mongodb4.4 中已经不再支持该配置(Master/slave replication is no longer supported),所以后面就不再给出配置示例了。
ReplicaSet 模式
说明
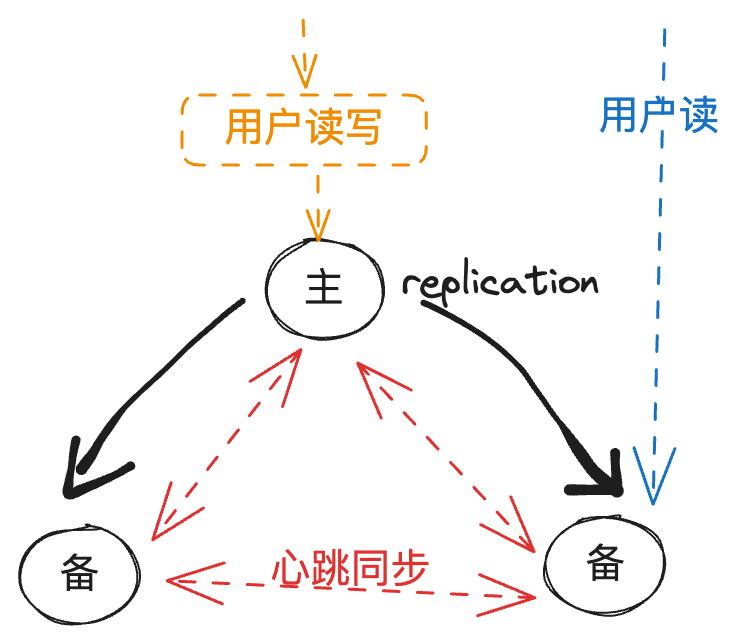
复制集(Replica Set)是一种高可用性和数据冗余的部署模式。复制集由一个或多个节点组成,其中包括一个主节点(Primary)和多个从节点(Secondary),还可以有一个仲裁节点(Arbiter)。 复制集的工作原理如下:
主节点(Primary):主节点是复制集的核心节点,负责处理所有的写操作(写入和更新),并将写操作的数据复制到从节点。主节点还负责处理读操作(如果读操作没有指定特定的读偏好),它可以向客户端提供数据。
从节点(Secondary):从节点是主节点的副本,它们复制主节点上的数据并提供读操作的能力。从节点通过与主节点保持心跳连接来保持同步,并定期从主节点复制数据。从节点也可以接收读操作,但默认情况下,它们不参与写操作。
仲裁节点(Arbiter):仲裁节点是一个特殊类型的节点,它不存储数据,仅用于在主节点和从节点之间进行投票决策。仲裁节点可以帮助解决主节点故障时的选举问题,它不需要较高的硬件资源。
该模式相比已经被弃用的master-slave模式,有如下优点:
自动故障转移:当主节点发生故障时,复制集可以自动选择一个新的主节点,无需手动干预。这提供了更高的可用性和容错性,减少了服务中断的风险。
数据一致性:复制集使用了选举机制来选择主节点,并确保所有从节点与主节点保持数据同步。这样可以确保复制集中的数据一致性,避免了主从复制中的数据延迟和数据不一致的问题。
动态扩展:复制集支持动态地添加和删除节点,以适应不断变化的需求。新节点可以作为从节点加入复制集,并且在需要时可以升级为主节点,从而扩展读和写的能力。
结构图
一般来说,ReplicationSet 官网推荐的生产环境最小配置为 3 个节点:1 个 Primary,2 个 Secondary,关于副本集的节点数和角色,有如下规则:
仲裁:资源紧张的情况下,即一主一从时,可以设置一个 Arbiter 仲裁节点
投票: 副本集最多可以有 50 名成员,但只有 7 名投票成员
投票: 当多于 2 个节点时。推荐副本集成员为奇数个成员
投票: 投票节点数量超过总节点数的半数才能进行投票,官方提供的节点故障容忍个数
这种规则下的节点数对应关系如下表:
节点数
选举新节点需要个
可容忍故障节点数
3
2
1
4
3
1
5
3
2
6
4
2
缺点
结构更加复杂,配置和维护成本上升
类似 Redis,因为每个节点之间都有心跳包,导致节点的心跳几何倍数增大,所以需要限制最多 50 名成员
Sharding 模式
说明
关于分片的原理、数据量过大导致的单节点瓶颈、水平扩展、垂直扩展等术语在 MySQL 和 Redis 的主从复制文章都有讲述,这里就不再强调一遍了。
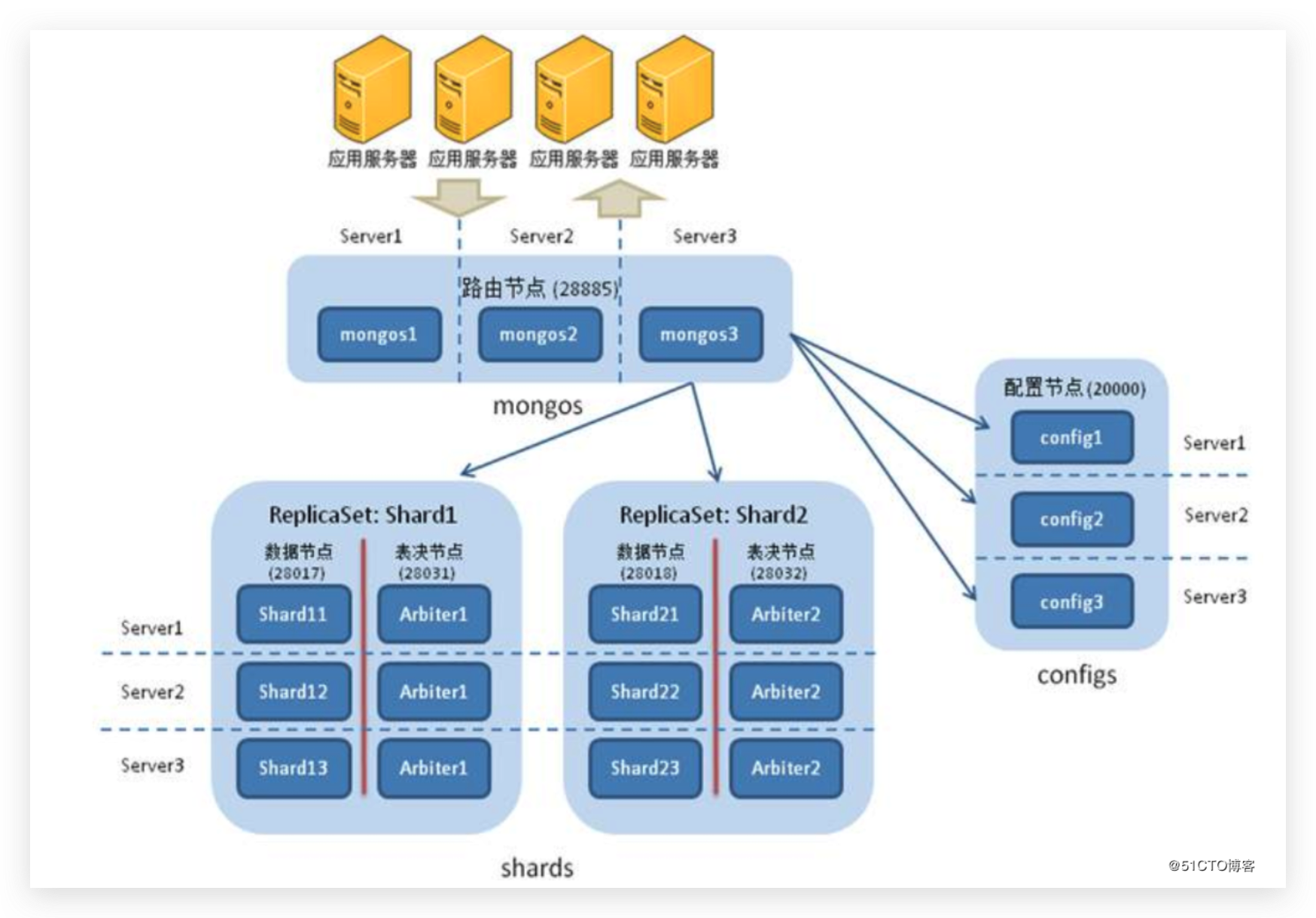
MongoDB 的 Sharding 是一种数据分片技术,用于将数据分散存储在多个节点(分片)上,从而实现数据的水平扩展和负载均衡。通过 Sharding,MongoDB 可以处理大规模数据集和高并发访问的需求。 整个集群由如下几个部分构成:
mongos:路由是mongos进程,作为应用程序和 Sharding 集群之间的中间层,负责将客户端请求路由到相应的分片上。
Config Server:配置服务器存储了 Sharding 集群的元数据信息,包括分片的配置信息、分片键范围等。通常配置服务器以复制集的形式部署,提供数据的冗余和高可用性。
replica set:副本集类似 Redis 的集群,或者所有的分布式系统,他们的分片都是将高可用结构视为一个原子,然后基于该视角进行数据的分片处理
Shard:每个分片是一个独立的 MongoDB 实例,存储数据的一部分。分片可以是单个服务器、副本集或分片集群,这里一般指代一个副本集
上述几个部分就组成了分片的四个基础组件: mongos,config server,shard,replica set。整个分片过程如下:
配置分片集群:首先需要准备分片集群的基础架构。这包括配置服务器(Config Server)和至少一个或多个分片服务器(Shard Server)。配置服务器用于存储分片集群的元数据信息,而分片服务器用于存储实际的数据。配置服务器可以以复制集的形式部署,以提供高可用性和冗余。
定义分片键(Shard Key):选择一个字段作为分片键,用于将数据分布到不同的分片上。分片键应根据数据的访问模式和查询需求选择,并且应具有良好的数据分布特性,以避免数据倾斜和热点问题。
启用分片:在 MongoDB 中,可以将一个数据库启用分片,使其成为分片集群的一部分。通过运行sh.enableSharding(database)命令,将数据库标记为可分片的状态。
创建分片集合:对于需要分片的集合,可以使用sh.shardCollection(namespace, shardKey)命令将其分片。其中,namespace表示集合的命名空间(数据库名和集合名的组合),shardKey表示用作分片键的字段。
数据迁移和负载均衡:一旦集合被分片,MongoDB 会自动将数据按照分片键的值进行分布到不同的分片上。在数据迁移过程中,MongoDB 会根据数据的分片键值范围,将数据从一个分片迁移到另一个分片。同时,分片集群会自动进行负载均衡,将数据均匀分布在不同的分片上,以实现数据的高可用性和性能优化。
结构
下面是一个三个分片(即三个副本集)的分布式结构:
其中,每个副本集都包含一主两从结构,除此之外还增加了 configserver、mongos 配置。
副本集 配置 在 Centos8 下,我们准备了三台 MongoDB 实例,其 IP 和端口分别是:主-10.0.28.16, 备:10.0.28.13,10.0.28.7
在三台服务器上创建相同的目录
1 2 3 4 5 6 7 8 9 10 [root@VM-28-13-opencloudos mongo] . ├── conf │ └── mongod.conf ├── data └── log 3 directories, 1 file [root@VM-28-13-opencloudos mongo] /app/mongo
编辑 mongod.conf 配置:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 systemLog: destination: file logAppend: true path: /app/mongo/log/mongod.log storage: dbPath: /app/mongo/data journal: enabled: true processManagement: fork: true timeZoneInfo: /usr/share/zoneinfo net: port: 27017 bindIp: 0.0.0.0 replication: replSetName: rs0
启动 mongod 服务,因为三个节点都不在一个服务器上,这里就使用默认的端口
1 2 3 4 [root@VM-28-16-opencloudos mongo] about to fork child process, waiting until server is ready for connections. forked process: 2663101 child process started successfully, parent exiting
配置复制集
注意,此时如果直接使用 mongo 连接数据库并执行show databases实际上会报错:not master and slaveOk=false,所以此时还需要在主节点进行配置:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 [root@VM-28-16-opencloudos mongo] > rs.initiate({ ... _id: "rs0" , members: [{ ... _id: 0, ... host: "10.0.28.16:27017" ... },{ ... _id: 1, ... host: "10.0.28.13:27017" ... },{ ... _id: 2, ... host: "10.0.28.7:27017" ... }] ... }) { "ok" : 1 }
在上面的配置成功之后,退出并重新登录 Mongo 交互界面,此时会发现终端提示框已经变化
1 2 3 4 5 6 7 8 9 10 11 12 13 [root@VM-28-16-opencloudos mongo] rs0:PRIMARY> show databases; admin 0.000GB config 0.000GB local 0.000GB[root@VM-28-13-opencloudos mongo] rs0:SECONDARY> rs0:SECONDARY> rs.status()
测试
命令行测试
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 rs0:PRIMARY> use bamboo switched to db bamboo rs0:PRIMARY> db.col.insert({name: 'test' }) WriteResult({ "nInserted" : 1 }) rs0:PRIMARY> db.col.find { "_id" : ObjectId("64afc40b560a377f00060f8d" ), "name" : "test" } rs0:SECONDARY> use bamboo switched to db bamboo rs0:SECONDARY> db.col.find() Error: error: { "topologyVersion" : { "processId" : ObjectId("64afc1319236068224ba1c5a" ), "counter" : NumberLong(4) }, "operationTime" : Timestamp(1689240758, 2), "ok" : 0, "errmsg" : "not master and slaveOk=false" , "code" : 13435, "codeName" : "NotPrimaryNoSecondaryOk" , "$clusterTime " : { "clusterTime" : Timestamp(1689240758, 2), "signature" : { "hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA=" ), "keyId" : NumberLong(0) } } } rs0:SECONDARY> db.secondaryOk() rs0:SECONDARY> db.col.find { "_id" : ObjectId("64afc40b560a377f00060f8d" ), "name" : "test" }
代码测试
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import randomfrom pymongo import MongoClientclient = MongoClient('mongodb://10.0.28.13:27017,10.0.28.16:27017,10.0.28.7:27017/?replicaSet=rs0' ) db = client.bamboo collection = db.col2 for i in range (10 ): data = {"name" : f"Number{i + 1 } " , "age" : 20 + i} collection.insert_one(data) for i in range (100 ): key = random.randint(1 , 10 ) result = collection.find_one({"name" : f"Number{key} " }) print (result) client.close()
故障转移
在主节点上主动触发 master 的退位
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 rs0:PRIMARY> rs.stepDown { "ok" : 1, "$clusterTime " : { "clusterTime" : Timestamp(1689241281, 1), "signature" : { "hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA=" ), "keyId" : NumberLong(0) } }, "operationTime" : Timestamp(1689241281, 1) } [root@VM-28-16-opencloudos mongo] rs0:SECONDARY> rs.secondaryOk() rs0:SECONDARY> show databases; admin 0.000GB bamboo 0.000GB config 0.000GB local 0.000GB
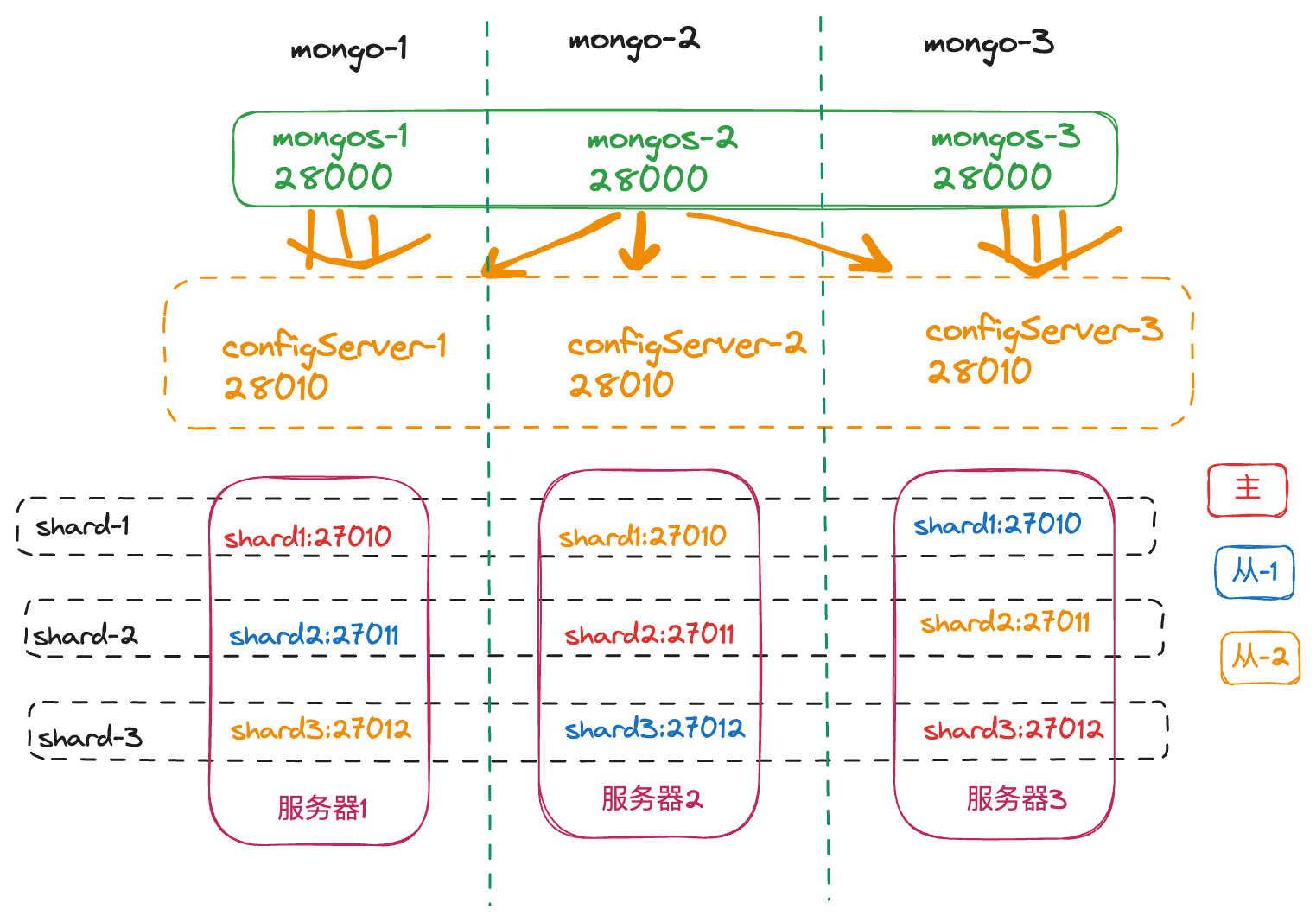
分片集群 物理结构 其各个服务和端口信息如下:
主机名
IP 地址
组件 mongos
组件 config server
shard
mongodb-1
10.0.28.16
端口:28000
端口:28010
主节点:27010,副本节点:27012,27011
mongodb-2
10.0.28.13
端口:28000
端口:28010
主节点:27011,副本节点:27010,27012
mongodb-3
10.0.28.7
端口:28000
端口:28010
主节点:27012,副本节点:27011,27010
其中,每一个副本集为了高可用考虑,副本集的三个节点分别部署在三台服务器上,并且三个垂直维度的分片的主节点不能在同一个服务器节点上(按理来说,应该部署 9 台服务器),结构图如下:
注意,每个分片都是一个副本集,类似上面章节的配置,一个分片就统一暴露一个接口,并且三个节点都部署在三个不同的服务器上。
configServer 配置 整体资源如下: 三台服务器,每台服务器上部署一个副本集(一主二从),每台服务器部署相应的 config server 和 mongos server。
目录结构
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 [root@VM-28-16-opencloudos mongo] /app/mongo/ ├── mongoconf │ ├── conf │ ├── data │ └── log ├── mongos │ ├── conf │ └── log ├── shard1 │ ├── conf │ ├── data │ └── log ├── shard2 │ ├── conf │ ├── data │ └── log └── shard3 ├── conf ├── data └── log 19 directories, 0 files
配置 config server
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 cat >/app/mongo/mongoconf/conf/mongoconf.conf<<EOF dbpath=/app/mongo/mongoconf/data logpath=/app/mongo/mongoconf/log/mongoconf.log#定义config server日志文件 logappend=true port = 28010 bind_ip = 0.0.0.0 maxConns = 1000#链接数 journal = true#日志开启 journalCommitInterval = 200 fork = true#后台执行 syncdelay = 60 oplogSize = 1000 configsvr = true#配置服务器 replSet=replconf#config server配置集replconf EOF mongod -f /app/mongo/mongoconf/conf/mongoconf.conf [root@VM-28-16-opencloudos mongo] tcp 0 0 127.0.0.1:28010 0.0.0.0:* LISTEN 2741150/mongod [root@VM-28-16-opencloudos mongo] > use admin switched to db admin config = { _id:"replconf" ,members:[ {_id:0, host:"10.0.28.16:28010" }, {_id:1, host:"10.0.28.13:28010" }, {_id:2, host:"10.0.28.7:28010" }, ]} rs.initiate(config); replconf:PRIMARY> rs.status()
此时,可以看到 config server 集群已经配置成功。
Shard 集群配置
配置 shard(副本集)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 cat >/app/mongo/shard1/conf/shard.conf <<EOF dbpath=/app/mongo/shard1/data logpath = /app/mongo/shard1/log/shard1.log port = 27010 bind_ip = 0.0.0.0 logappend = true #nohttpinterface = true fork = true oplogSize = 4096 journal = true #engine = wiredTiger #cacheSizeGB = 38G #smallfiles=true shardsvr=true #shard服务器 replSet=shard1 #副本集名称shard1 EOF
启动服务
1 2 3 4 5 6 7 8 9 10 [root@VM-28-16-opencloudos mongo] about to fork child process, waiting until server is ready for connections. forked process: 2751352 child process started successfully, parent exiting [root@VM-28-16-opencloudos mongo] tcp 0 0 0.0.0.0:27010 0.0.0.0:* LISTEN 2751352/mongod tcp 0 0 0.0.0.0:28010 0.0.0.0:* LISTEN 2745638/mongod
测试服务是否正常并在mongo-1服务器上进行 shard1 的初始化工作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 [root@VM-28-16-opencloudos mongo] > use admin switched to db admin config = {_id:"shard1" ,members:[ {_id:0,host:"10.0.28.16:27010" }, {_id:1,host:"10.0.28.13:27010" }, {_id:2,host:"10.0.28.7:27010" },] } rs.initiate(config); shard1:PRIMARY> rs.status()
至此,shard1 的配置和启动已经完成,后续 shard2 的配置也是类似的逻辑,只不过改下端口和路径
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 cat >/app/mongo/shard2/conf/shard.conf <<EOF dbpath=/app/mongo/shard2/data logpath = /app/mongo/shard2/log/shard1.log port = 27011 bind_ip = 0.0.0.0 logappend = true #nohttpinterface = true fork = true oplogSize = 4096 journal = true #engine = wiredTiger #cacheSizeGB = 38G #smallfiles=true shardsvr=true #shard服务器 replSet=shard2 #副本集名称shard1 EOF mongod -f /app/mongo/shard2/conf/shard.conf mongo 10.0.28.13:27011 use admin config = {_id:"shard2" ,members:[ {_id:0,host:"10.0.28.16:27011" }, {_id:1,host:"10.0.28.13:27011" }, {_id:2,host:"10.0.28.7:27011" },] } rs.initiate(config);
shard3 的配置:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 cat >/app/mongo/shard3/conf/shard.conf <<EOF dbpath=/app/mongo/shard3/data logpath = /app/mongo/shard3/log/shard1.log port = 27012 bind_ip = 0.0.0.0 logappend = true #nohttpinterface = true fork = true oplogSize = 4096 journal = true #engine = wiredTiger #cacheSizeGB = 38G #smallfiles=true shardsvr=true #shard服务器 replSet=shard3 #副本集名称shard1 EOF mongod -f /app/mongo/shard3/conf/shard.conf mongo 10.0.28.7:27012 use admin config = {_id:"shard3" ,members:[ {_id:0,host:"10.0.28.16:27012" }, {_id:1,host:"10.0.28.13:27012" }, {_id:2,host:"10.0.28.7:27012" },] } rs.initiate(config); shard3:PRIMARY>
mongos 配置 由于 mongos 服务器的配置是从内存中加载,所以自己没有存在数据目录 configdb 连接为配置服务器集群
配置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 cat >/app/mongo/mongos/conf/mongos.conf<<EOF logpath=/app/mongo/mongos/log/mongos.log logappend=true port = 28000 bind_ip = 0.0.0.0 maxConns = 1000 configdb=replconf/10.0.28.16:28010,10.0.28.13:28010,10.0.28.7:28010 #制定config server集群 fork = true EOF mongos -f /app/mongo/mongos/conf/mongos.conf [root@VM-28-16-opencloudos mongo] tcp 0 0 0.0.0.0:27010 0.0.0.0:* LISTEN 2751352/mongod tcp 0 0 0.0.0.0:27011 0.0.0.0:* LISTEN 2753991/mongod tcp 0 0 0.0.0.0:27012 0.0.0.0:* LISTEN 2758042/mongod tcp 0 0 0.0.0.0:28000 0.0.0.0:* LISTEN 2759127/mongos tcp 0 0 0.0.0.0:28010 0.0.0.0:* LISTEN 2745638/mongod
启动分片,在任意一台服务器上登录 mongos
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 [root@VM-28-16-opencloudos mongo] mongos> use admin switched to db admin mongos> db.runCommand({addshard:"shard1/10.0.28.16:27010,10.0.28.13:27010,10.0.28.7:27010" }) { "shardAdded" : "shard1" , "ok" : 1, "operationTime" : Timestamp(1689263158, 3), "$clusterTime " : { "clusterTime" : Timestamp(1689263158, 3), "signature" : { "hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA=" ), "keyId" : NumberLong(0) } } } db.runCommand({addshard:"shard2/10.0.28.16:27011,10.0.28.13:27011,10.0.28.7:27011" }) db.runCommand({addshard:"shard3/10.0.28.16:27012,10.0.28.13:27012,10.0.28.7:27012" }) mongos> sh.status() --- Sharding Status --- sharding version: { "_id" : 1, "minCompatibleVersion" : 5, "currentVersion" : 6, "clusterId" : ObjectId("64b00f8c862a9e98add8a740" ) } shards: { "_id" : "shard1" , "host" : "shard1/10.0.28.13:27010,10.0.28.16:27010,10.0.28.7:27010" , "state" : 1 } { "_id" : "shard2" , "host" : "shard2/10.0.28.13:27011,10.0.28.16:27011,10.0.28.7:27011" , "state" : 1 } { "_id" : "shard3" , "host" : "shard3/10.0.28.13:27012,10.0.28.16:27012,10.0.28.7:27012" , "state" : 1 }
测试
若需要测试分片,则需要提前连接 mongos,让指定的数据库和结合进行分片
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 [root@VM-28-16-opencloudos mongo] mongos> use admin switched to db admin mongos> db.runCommand( { enablesharding :"kaliarchdb" }) { "ok" : 1, "operationTime" : Timestamp(1689263434, 4), "$clusterTime " : { "clusterTime" : Timestamp(1689263434, 5), "signature" : { "hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA=" ), "keyId" : NumberLong(0) } } } mongos> db.runCommand( { shardcollection : "kaliarchdb.table1" ,key : {_id:"hashed" } } ) { "collectionsharded" : "kaliarchdb.table1" , "collectionUUID" : UUID("14c08ee8-3aa5-4beb-b319-ffe999347705" ), "ok" : 1, "operationTime" : Timestamp(1689263441, 36), "$clusterTime " : { "clusterTime" : Timestamp(1689263441, 36), "signature" : { "hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA=" ), "keyId" : NumberLong(0) } } } mongos> db.runCommand({listshards:1}) { "shards" : [ { "_id" : "shard1" , "host" : "shard1/10.0.28.13:27010,10.0.28.16:27010,10.0.28.7:27010" , "state" : 1 }, { "_id" : "shard2" , "host" : "shard2/10.0.28.13:27011,10.0.28.16:27011,10.0.28.7:27011" , "state" : 1 }, { "_id" : "shard3" , "host" : "shard3/10.0.28.13:27012,10.0.28.16:27012,10.0.28.7:27012" , "state" : 1 } ], "ok" : 1, "operationTime" : Timestamp(1689263486, 2), "$clusterTime " : { "clusterTime" : Timestamp(1689263486, 2), "signature" : { "hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA=" ), "keyId" : NumberLong(0) } } }
通过 mongos 客户端(对外暴露),测试数据的插入
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 [root@VM-28-16-opencloudos mongo] mongos> use kaliarchdb; switched to db kaliarchdb mongos> for (var i = 1; i <= 100000; i++) db.table1.save({_id:i,"test1" :"testval1" }); WriteResult({ "nMatched" : 0, "nUpserted" : 1, "nModified" : 0, "_id" : 100000 }) mongos> db.table1.stats { "sharded" : true , "capped" : false , "ns" : "kaliarchdb.table1" , "count" : 100000, "size" : 3800000, "storageSize" : 1261568, "totalIndexSize" : 4960256, "totalSize" : 6221824, "indexSizes" : { "_id_" : 1630208, "_id_hashed" : 3330048 }, "avgObjSize" : 38, "maxSize" : NumberLong(0), "nindexes" : 2, "nchunks" : 6, "shards" : { "shard1" : { "ns" : "kaliarchdb.table1" , "size" : 1282690, "count" : 33755, "avgObjSize" : 38, "storageSize" : 405504, "freeStorageSize" : 94208, "capped" : false , "nindexes" : 2, "indexBuilds" : [ ], "totalIndexSize" : 1515520, "totalSize" : 1921024, }, "shard3" : { "ns" : "kaliarchdb.table1" , "size" : 1257876, "count" : 33102, "avgObjSize" : 38, "storageSize" : 417792, "freeStorageSize" : 98304, "capped" : false , "nindexes" : 2, "indexBuilds" : [ ], "totalIndexSize" : 1736704, "totalSize" : 2154496, }, "shard2" : { "ns" : "kaliarchdb.table1" , "size" : 1259434, "count" : 33143, "avgObjSize" : 38, "storageSize" : 438272, "freeStorageSize" : 114688, "capped" : false , "nindexes" : 2, "indexBuilds" : [ ], "totalIndexSize" : 1708032, "totalSize" : 2146304, } }, "ok" : 1, "operationTime" : Timestamp(1689263803, 4), "$clusterTime " : { "clusterTime" : Timestamp(1689263803, 4), "signature" : { "hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA=" ), "keyId" : NumberLong(0) } } }
这个好复杂。。。。。。。。
参考
 alipay
alipay







