站内链接:
文件相关:
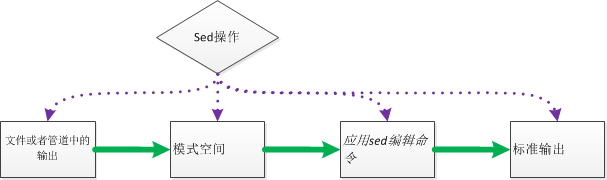
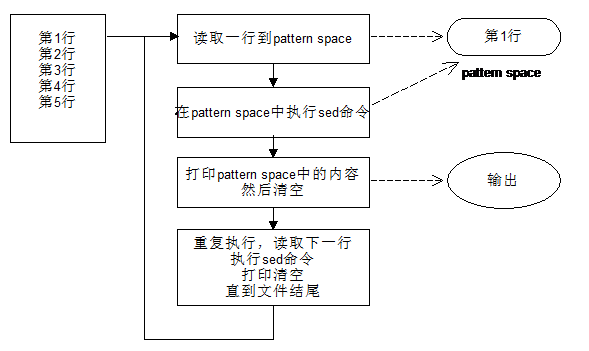
介绍 功能 stream editor(流编辑器), 读取输入文件的行进行命令匹配, 对于匹配到的行进行删除, 替换, 插入, 打印等操作. 其整体的工作模式类似 vim 的文件缓存, sed 会将读取到的行临时缓存到pattern space中, 在处理完缓存区的行之后再进行回写到保持空间, 打印等操作, 重复上述操作直到文件末尾.
模式空间
sed 拥有两种空间概念:
1 2 3 4 5 6 7 h PS拷贝到HS中 H PS附加到HS中 g HS拷贝到PS中 G HS附加到PS中 x 交换HS和PS之间的内容
sed 的操作简易流程:
详细处理数据流程:
Command 命令格式 sed 命令 FORMAT 格式:
1 2 sed OPTIONS command input_file sed OPTIONS SCRIPT INPUTFILES
其中 options 如下:
1 2 3 4 5 6 7 8 9 10 -n -e script -E -f script-file -i -r -s -u
command 这里先列出所有的命令说明, 后续再逐一对各个命令进行详细说明.
s 替换命令: [address]s/pattern/replacement/flags
d 删除命令: [address]d 或者 /pattern/d
p 打印命令: [address]p 或者 /pattern/p
a 追加命令: [address]a\new string 或者 /pattern/a\new string
i 前插命令: [address]i\new string 或者 /pattern/i\new string
c 替换命令: [address]c\new string 或者 /pattern/c\new string
w 重定向到文件, 将匹配行写入特定文件: [address]w filename
跳转命令 b-跳转命令:
1 2 3 命令:b(branch) 功能:类似C代码,调到command集合中指定的label处,循环操作 格式:[address]b [label]
t-测试命令:
1 2 3 命令:t 功能:基于上一条命令是否匹配,成功匹配则跳过下一条command 格式:[address]t [label]
地址区间
address 格式:
1 2 3 4 5 6 7 [address]command 或者 [address]{ command1 command2 ... }
数字范围过滤:
1 2 3 first,second first到second $ 最后一行 first, ~N first到first+N
文本模式过滤:
1 2 /pattern/command /p1/,/p2/command p1到p2之间的所有文本
地址区间:
1 2 3 number 单一行号 first~step 指定开始行和step first, +N first开始的N行
另外, 关于正则表达式(BRE, ERE)见三剑客-grep 中的语法介绍, 链接见文章首部.
命令集 substitude 命令格式:[address]s/pattern/replacement/flags, 其中 flags 标记:
1 2 3 4 5 g Apply the replacement(替换、代替) to all matches to the regexp, not just the first. n 1~512 之间的数字, 表示指定要替换的字符串出现第几次时才进行替. p 如果替换发生, then print the new pattern space.一般和-n一起连用,仅仅打印替换行信息 w file 如果替换发生, then write out the result to the named file.格式:s/regexp/replacement/w resultFile \n 匹配第n个子串, 之前在(pattern)中定义的
简单例子如下:
1 2 3 4 5 6 7 8 sed 's/test/trial/2' data4.txt sed 's/test/trial/g' data4.txt sed -n 's/test/trial/p' data5.txt sed 's/test/trial/w test.txt' data5.txt
delete 1 2 3 4 5 6 7 命令:d 功能:删除匹配的行 格式:[address]d 或者 /pattern/d 命令:D 功能:多行删除命令,仅删除模式空间中到\n为止的所有字符(即第一行) 产生原因:N和d混用,可能出现误删操作,见下面的例子
简单例子:
1 2 3 4 5 6 sed 'd' data1.txt sed '3d' data6.txt sed '/1/,/3/d' data6.txt
插入和附加命令 1 2 3 4 5 命令:i/a 功能:插入(在指定行前增加新行),附加(在指定行后增加新行) 格式: sed '[address]command\ new line' inputfile
简单例子:
1 2 3 4 5 6 7 8 sed '3i\This is an inserted line.' data6.txt sed '3a\This is an inserted line.' data6.txt sed '3i\ this is one \ this is two' data6.txt
修改命令 1 2 3 命令:c 功能:修改数据流中的整行内容 格式:同插入、附加命令
转换命令 1 2 3 4 5 命令:y(transform) 功能:将同等长度的字符串替换为同等长度的另外一个字符串 格式: sed '[address]/inchars/outchars/' intputfile PS:inchars和outchars必须相等
打印命令 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 命令:p 功能:打印文本行,与-n连用 格式:数字范围过滤、文本模式过滤 命令:P 功能:多行打印命令,仅打印模式空间中到\n为止的所有字符(即第一行) 使用:常常和D、N一起使用,便利输出整个文本(D命令) 命令:= 功能:打印行号 格式:数字范围过滤、文本模式过滤 命令:l 功能:列出行 格式:数字范围过滤、文本模式过滤
多行命令 1 2 3 4 5 命令:n 功能:默认方式,单行上的处理,基于\n将输入流分成行 命令:N 功能:将数据流中的两个文本行合并到同一个模式空间中(包含\n换行)
排除命令(非) 1 2 3 命令:! 功能:使当前命令不要作用于指定的特定地址或者区间,但是会作用于该区间之外的地址 格式:!command
示例 删除 1 2 3 4 5 6 7 8 9 10 11 sed '2,$d' test.txt sed '/^bifeng/d' test.txt sed '/first/, /second/d' test.txt sed 'N ; /first\nSecond/D' test.txt sed 'N ; /first\nSecond/d' test.txt
打印 1 2 3 4 5 6 7 8 9 10 11 12 sed -n '/^ruby/p' test.txt sed -n '/^$/=' test.txt sed -n 'l' test.txt sed -n '{ N P D}' file
PS:D 命令每次执行完后会自动返回脚本(命令脚本)的起始处
插入/附加 1 2 3 4 sed '1a drink tea' test.txt sed '1i drink tea' test.txt
替换 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 grep -r -l "lagou" .|xargs sed -i "s/lagou/kuang/g" sed -i 's/\o240\|\o302//g' crypt-aes.c grep "/home/xinshu/" -r -l .|xargs sed -i -e "s/\/Users\/bamboo\//\/Users\/zhengbifeng\//g" grep "/home/xinshu/" -r -l .|xargs sed -ibk -e "s/\/home\/xinshu\//\/Users\/bamboo\//g" grep "date:" -r -l languages| xargs sed -i -e -E 's/date: (.*)T(.*)\+08:00/time: \1 \2/g' egrep "time:( [0-9]{4}-[0-9]{2}-[0-9]{2} [0-9]{2}:[0-9]{2}:[0-9]{2})" -r -l . | xargs \ sed -i -e -E 's/time: ([0-9]{4}-[0-9]{2}-[0-9]{2}) ([0-9]{2}:[0-9]{2}:[0-9]{2})/date: \1 \2/g' find . -type f -exec grep -E "unusebamboo.top/algorithm.*(png|jpg|jpeg)" {} \; -exec sed -i -E 's|unusebamboo.top/algorithm|unusebamboo.top/blog/algorithm|g' {} + find . -type f -name "*.md" -exec sed -i '' -E 's/^(#+) [0-9]+(\.[0-9]+)* /\1 /g' {} +
注意, 在 MacOS 上, 需要在每一个 sed 命令前面增加: LC_ALL=C
错误:
1 2 3 4 5 6 (Error: illegal bytes) sed在识别含有"多字节编码" 遇到解析冲突问题, 需要手动更改语言编码环境, 让 MAC正确处理单字节和多字节,但是不建议覆盖本地 Locale. export LC_CTYPE=C ; export LANG=C; + 具体的替换操作命令
修改/转换 1 2 3 4 5 sed '3c This is a changed line of text' file sed '3y/first/12345/' first
跳转/测试 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 sed '{ /first/b jump1 s/This is the/No jump on/ :jump1 s/This is the/Jump here on/}' file2sed '{ s/first/matched/ t s/This is the/No match on/ }' file2
高级例子 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 sed '$!G' data2 sed '{ /^$/d $!D}' file1sed '{ :start $q N 11,$D b start}' file1
引用
 alipay
alipay






