数据库:Redis配置和优化
站内链接:
安装和配置
mac
安装:
brew install redis配置:
1 | # A. 通过launchctl启动配置 |
- redis 客户端安装
1 | # Install brew cask |
ubuntu
- 安装
1 | # A. Install build-essential and tcl |
- 配置
1 | # A. 拷贝配置文件 |
- 启动 redis
1 | # Start |
日志
- 设置,通过 redis.conf 中的 loglevel、logfile 进行配置
1 | # 日志等级: debug, verbose, notice, warning |
- 日志输出格式解析
对于如下的一行日志输出:332845:M 06 Jul 2023 09:43:44.893 * Background saving terminated with success,其代表的含义如下:
332845:表示记录的进程 ID(Process ID),即生成该日志记录的 Redis 进程的唯一标识符。M:表示上下文相关标识符,M-主节点、S-从节点、C-客户端、A-集群、R-复制、D-持久化、P-持久化方式、T-事务06 Jul 2023 09:43:44.893:时间戳,指示日志记录的时间点,格式为年月日时分秒毫秒。* Background saving terminated with success:具体的日志内容,表示后台保存操作成功终止的信息。
例如下面的一个报错日志(没有日志等级有点奇怪):47960:S 16 Apr 12:05:43.085 * Discarding previously cached master state.,其解析输出结果如下:
47960:进程 ID,表示生成该日志的 Redis 从节点(Slave)进程的唯一标识符。S:标识符,表示该日志是从节点(Slave)的相关信息。16 Apr 12:05:43.085:时间戳,指示日志记录的时间点,格式为月份、日期、小时、分钟、秒以及毫秒。* Discarding previously cached master state.:具体的日志内容,表示从节点正在丢弃先前缓存的主节点状态。
持久化
RDB
RDB 是 Redis 默认采用的持久化方式(快照方式),在 redis.conf 配置文件中的配置说明如下:
1 | # <seconds> 表示自最后一次修改数据后经过多少秒后开始执行快照,<changes> 表示自最后一次修改数据后经过多少次修改后开始执行快照 |
注意,这三条命令是或的关系,其中默认会将快照数据存储到配置项:${dir}/${dbfilename}中,其中 dir 和 dbfilename 在 redis.conf 中皆有配置,默认是:/var/lib/redis/dump.rqb,下面是一个持久化的测试例子(centos):
1 | 1. 在redis中添加10条命令:name1, ..., name10 |
最后,再简单的介绍一下 RDB 快照的流程:
- a. 调用 fork 函数创建持久化子进程
- b. 子进程将指定数据集从内存写入到临时的 rdb 快照文件中
- c. redis 使用这个新创建的临时 rdb 文件替换原来的 rdb 文件(删除旧文件)
AOF
- 配置
AOF(append-only file)持久化通过将 Redis 的写操作以追加的方式记录到一个文件(AOF 文件)中来实现数据持久化。AOF 文件是一个包含一系列 Redis 命令的文本文件,当需要恢复数据时,Redis 会重新执行 AOF 文件中的命令以还原数据。这个同 MySQL 的 binlog 日志非常相似,以一种原生命令的形式进行数据的增量备份而并非是类似 RDB 这种全量备份。
默认情况下,AOF 配置是关闭的,其配置如下:
1 | # 启用或禁用 AOF 持久化 |
- rewrite
AOF 机制存在一个问题,随着时间的增长,AOF 文件会越来越大,这明显是不符合需求的,所以系统需要定期的进行 AOF 重写操作。目前采用的方式是创建一个新的 AOF 文件,将数据库里的全部数据转换成协议的方式保存到文件中,通过此操作达到减少 AOF 文件大小的目的,重写后的大小一定是小于等于旧 AOF 文件的大小,其配置如下:
1 | # 当前写入日志文件的大小超过上一次rewrite之后的文件大小的百分之100,即2倍时自动触发Rewrite |
其中通过异步进行重写时会 fork 一个子进程进行重写操作,其中还涉及 AOF Buffer 以便处理重写期间的新增命令。
- 处理流程
下面是包含 AOF Rewrite 的处理流程:
- a. redis fork 一个子进程,子进程基于当前内存中的数据,构建日志,开始往一个新的临时的 AOF 文件中写入日志
- b. 在此期间,redis 主进程接收到的新的更改数据命令都会写入到 AOF Buffer 中
- c. 子进程写完新的 AOF 日志文件之后,redis 主进程将缓存中的新日志再次追加到新的 AOF 文件中
- d. 最后,用新的日志文件替换掉旧的日志文件
注意,并不是发送到 Redis 的所有命令都要记录到 AOF 日志里面,只有那些会导致数据发生修改的命令才会追加到 AOF 文件中。
- 配置和测试
通过线上 CONFIG 更改配置(redis.conf 配置在上面已经讲解):
1 |
|
此时,如果增加一条新的命令就会看到/var/lib/redis/appendonly.aof文件生成并新增了一条信息,这个相比 RDB 的持久化速度是更加快速的。
比较
- RDB 优点
- RDB 是一个非常紧凑(compact)的文件,它保存了 redis 在某个时间点上的数据集。这种文件非常适合用于进行备份和灾难恢复(将持久化到硬盘中的文件恢复即可)
- 生成 RDB 文件 的时候,redis 主进程会 fork() 一个子进程来处理所有保存工作,主进程不需要进行任何磁盘 IO 操作。
- RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。
- RDB 缺点
- 每次快照是保存整个数据集数据,可能触发快照时间比较长,比如 10 分钟进行一次,那么如果期间系统挂掉,就有几分钟数据丢掉。最后一次持久化后的数据可能丢失。
- 每次保存 rdb 快照文件,都需要 fork 一个子进程处理持久化工作,如果数据量庞大,可能非常耗时,造成服务器紧张,然后停止一段时间给客户端服务,因为每次都是
全量备份
- AOF 优点
- 更好的保护数据不丢失,一般 AOF 会每隔 1 秒,通过一个后台线程执行一次 fsync 操作,最多丢失 1 秒钟的数据
- 日志文件以 append-only 模式写入,所以没有任何磁盘寻址的开销,写入性能非常高
- 日志文件即使过大的时候,出现后台重写操作,也不会影响客户端的读写,通过 rewrite 方式避免了读取过大的日志文件
- 日志文件的命令通过可读(人性化,比如时间戳、上下文、级别标识等)的方式进行记录,这个特性非常适合做灾难性的误删除的紧急恢复
- AOF 缺点
- AOF 日志文件通常比 RDB 数据快照文件更大
- AOF 开启后,支持的写 QPS 会比 RDB 支持的写 QPS 低,因为 AOF 一般会配置成每秒 fsync 一次日志文件
- 较为复杂的基于命令日志/merge/回放的方式,比基于 RDB 每次持久化一份完整的数据快照文件的方式,更加脆弱一些
所以,在一些线上高 CPU 导致问题出现的时候,常常需要临时先将 AOF 关闭以增加服务的 QPS,降低 CPU 消耗。
线程
单线程
Redis 单线程指的是「接收客户端请求->解析请求 ->进行数据读写等操作->发生数据给客户端」这个过程的 IO 线程,这也是我们通常所说的 redis 是单线程的原因,但 redis 除了该主线程之外,还存在其他后台线程。
另外,redis 版本一直在变动中,Redis 6.0 之前一直使用单线程进行处理,在 Redis 6.0 开始采用了多个 I/O 线程来处理网络请求。那么,redis 的单线程是怎样一种机制,为何其可以达到官方所述的 10W/s 的并发?下面是 redis 最为津津热道的 epoll 事件循环,redis 单线程就是采用下面的单线程模式:
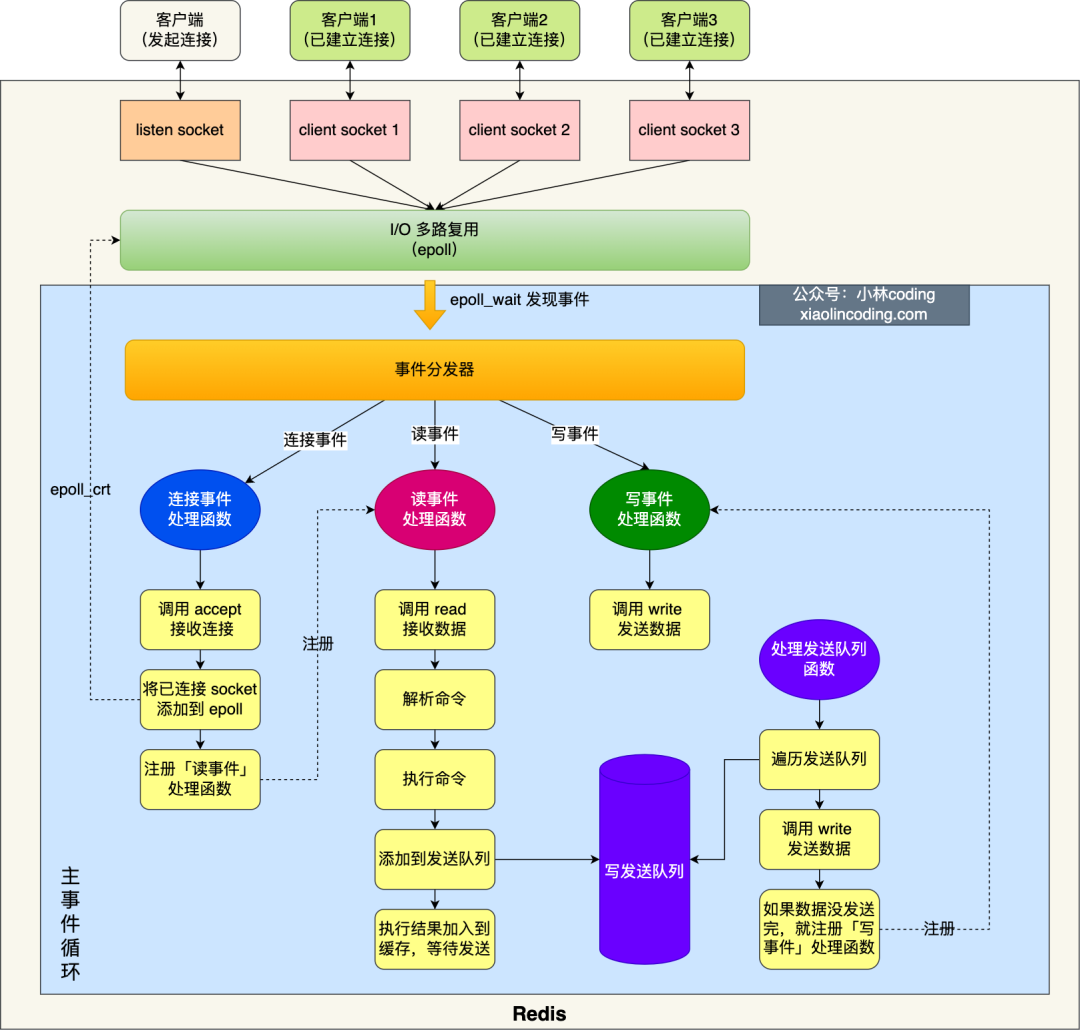
那么,为何 redis 使用单线程,并且其还达到了这么高的性能呢?除了上述的事件循环机制外还有其他原因吗?
- Redis 的大部分操作都在内存中完成,并且采用了高效的数据结构,Redis 瓶颈可能是机器的内存或者网络带宽而并非 CPU,所以使用单线程没问题
- 单线程模型可以避免了多线程之间的竞争,减小了设计复杂度、省去了切换带来的开销,带来了程序执行顺序的不确定性,多线程的开发难度和处理逻辑是远远高于单线程的
- 多路复用,即上面的 epoll 使用
那么,为何 redis 6.0 版本开始又开始引入了多线程呢?
- 支持的 I/O 多线程特性,其中多线程仅仅适用于写操作,读操作仍然使用单线程,除非开启配置:
io-threads-do-reads - 随着网络硬件的性能提升,性能瓶颈有时会出现在网络 I/O 的处理上,此时采用多线程可以提高 redis 的处理效率,Redis 官方表示,Redis 6.0 版本引入的多线程 I/O 特性对性能提升至少是一倍以上。
后台线程
实际上,redis 除了主线程之外,还存在多个后台线程,例如:
- RDB 持久化线程:负责执行 RDB 持久化操作,将内存中的数据保存到硬盘上的 RDB 文件中。
- AOF 后台重写线程:负责执行 AOF 重写操作,将 AOF 日志文件中的历史命令进行压缩和优化,生成新的 AOF 文件。
- AOF 文件写入线程:负责将新的命令写入 AOF 日志文件,保证数据的持久化。
- lazyfree 线程:执行 unlink key / flushdb async / flushall async 等命令,会把这些删除操作交给后台线程来执行,从而避免阻塞主线程
- 主从复制线程,Lua 脚本执行线程
所有这些后台线程都类似消费者的角色,他们通过消费各自消息队列中的耗时或复杂操作,减少主线程的阻塞。
优化配置
慢查询
慢查询日志功能用于记录执行时间超过给定时长的命令请求, 用户可以通过这个功能产生的日志来监视和优化查询速度:
slowlog-log-slower-than:选项指定执行时间超过多少微秒的命令请求会被记录到日志上slowlog-max-len:选项指定服务器最多保存多少条慢查询日志
可以通过config get slowlog-log-slower-than查看当前系统上是否已经配置了慢日志,如果未配置则可以通过config set配置并立即生效。
1 | # 1. 设置执行时间为0 |
长连接
Redis 连接有两种:长连接、短连接,他们的各自优势如下:
- 长连接:长连接更适合于高吞吐量而短连接更适合于交互型应用,但在长时间空闲时会增加服务器负载,容易造成内存泄漏,长连接适用于实时推送、持续订阅等场景。
- 短连接:短连接更适合于单次或少量请求的场景,若是频繁连接则会极大的消耗 CPU 资源。每次重新建连接引入的网络开销,而且连接的释放都需要
redis-server消耗额外的 CPU 周期进行清理工作。
若是频繁的建立连接,导致 Redis 实例的大量资源消耗在连接处理上,此时就会表现为 CPU 使用率就非常高、连接数高、但 QPS 未达预期的情况,此时就应该从业务端调整连接为长连接。
- 短连接测试用例
1 | import redis |
- 长连接测试用例
1 | import redis |
通过连接池创建的连接对象可以实现长连接的效果,即在多次 Redis 操作之间保持连接的状态。通过使用 Redis 长连接,可以避免频繁地创建和关闭连接,提高了 Redis 操作的效率和性能。
- redis 长短连接测试
下面是一个通过redis-benchmark进行长短连接测试的对比实验,测试对象为 redis server 6.2.4 版本
1 | # 1. 长连接测试,此时查看CPU,发现readQueryFromClient的占比是比较高的 |
在运行这些命令期间,使用 perf top 命令查看 listSearchKey(释放连接时会调用)和 readQueryFromClient 的 CPU 使用率,此时会发现短连接测试期间,前者的 CPU 占比远远高于后者,即大量的 CPU 时间损耗连接释放。
但若是并发连接数是 1000~2000 的时候,短连接测试的时候 listSearchKey 可能占比比较低。
限流
- setnx(固定窗口法)
SETNX命令是用于设置键的值,但仅在键不存在时才进行设置,通过 setnx 命令可以达到简单的访问频率限制,下面是一个示例代码:
1 | import redis |
在实际应用中,可能需要考虑分布式环境下的并发访问和多个限流键的管理。可以结合使用其他 Redis 命令和数据结构(如INCR, EXPIRE, ZSET等)来实现更复杂和灵活的限流策略。
另外,该方法无法应对两个时间边界内的突发流量,例如在计数器清零的前 1 秒以及清零的后 1 秒都进来了 N 个请求,那么在短时间内服务器就接收到了两倍的(2N 个)请求,这样可能压垮系统
- zset(滑动窗口法)
随着时间的推移,时间窗口(currentTime - limitWindowValue)也会持续移动,有一个计数器不断维护着窗口内的请求数量,这样就可以保证任意时间段内,都不会超过最大允许的请求数。
时间窗口的滑动和计数器可以使用 redis 的有序集合(sorted set)来实现。score 的值用毫秒时间戳来表示,可以利用 当前时间戳 - 时间窗口的大小 来计算出窗口的边界,然后根据 score 的值做一个范围筛选就可以圈出一个窗口;
1 | import time |
时间窗口法虽然避免了时间界限的问题,但是依然无法很好解决细时间粒度上面请求过于集中的问题,就例如限制了 1 分钟请求不能超过 60 次,请求都集中在 59s 时发送过来,这样滑动窗口的效果就大打折扣。
- 令牌桶法
以固定的速率生成令牌,把令牌放到固定容量的桶里,超过桶容量的令牌则丢弃,每来一个请求则获取一次令牌,规定只有获得令牌的请求才能放行,没有获得令牌的请求则丢弃。
1 | import time |
- 桶漏算法
不限制请求流入的速率,但是限制了请求流出的速率。这样突发流量可以被整形成一个稳定的流量,不会发生超频。
1 | import time |
参考
 alipay
alipay








