淘宝千万级并发分布式架构图解
本网站相关文章:
淘宝技术架构
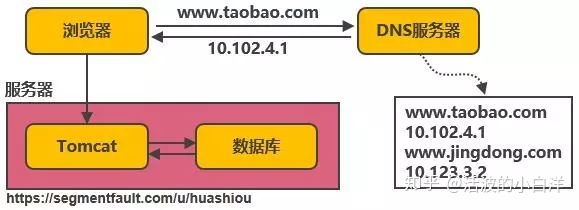
- 单机架构, 这是开发者最先接触的服务器架构:
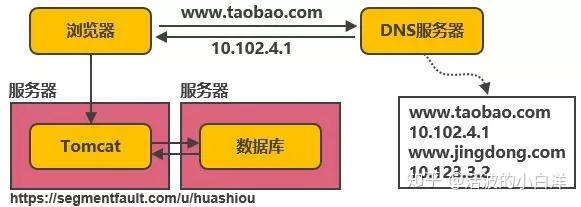
- 动态服务器和数据库分离, 以避免资源竞争
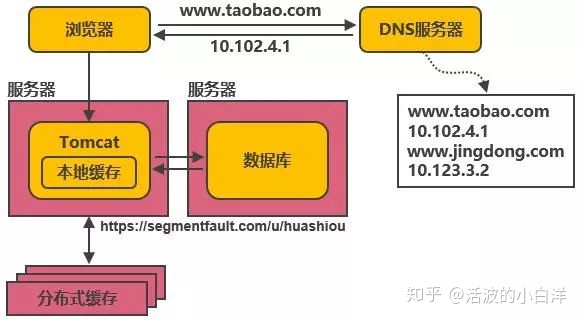
- 本地缓存和分布式缓存, 降低服务器和数据库的压力, 使用
memcached作为本地缓存,Redis作为
分布式缓存.
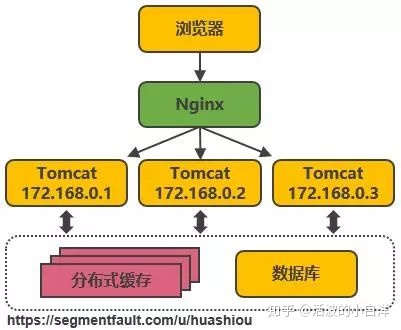
- 反向代理, 实现负载均衡, 使用 nginx 实现负载均衡, 将请求均匀的分发到每一个 web 服务器上, 其中
涉及 session 共享等问题
- 数据库读写分离, 以解决单机数据库的压力.
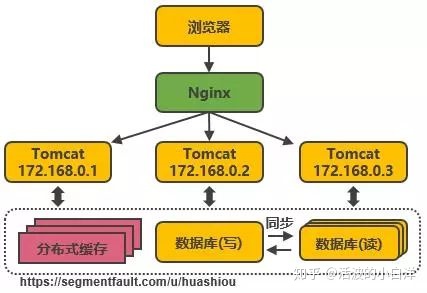
- 数据库业务分库, 将不同的业务保存到不同的数据库中, 降低业务之间的资源竞争, 当然跨业务之间
的表关联还需要额外的措施.
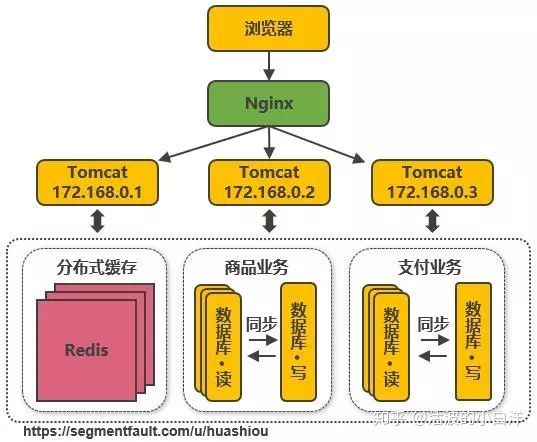
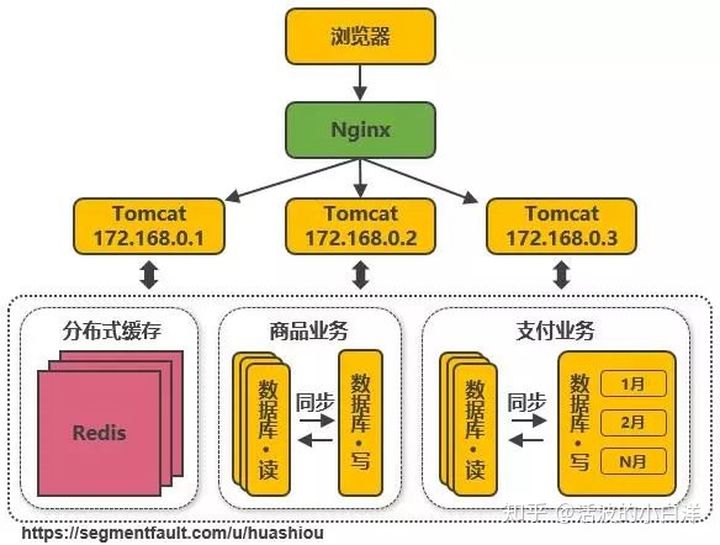
- 数据库表分离, 解决
单机写库性能瓶颈. 例如评论数据, 按照商品 ID 进行 HASH, 路由到对应表中
存储, 评论数据都是独享的. 当然, 此做法实际上就是分布式数据库.
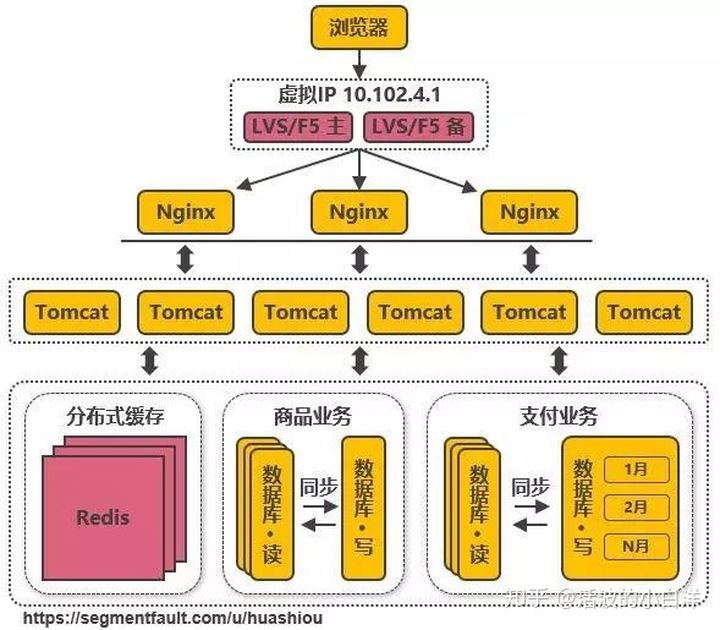
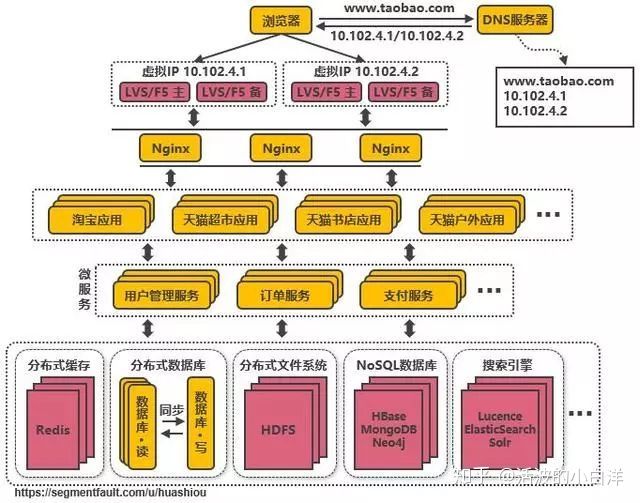
- 利用使用 LVS 或 F5 来使多个 Nginx 负载均衡. 从上面的几个服务器架构可以知晓, 不管如何分发, 所有
的请求都必须通过第一台 nginx, 即使使用两层的 nginx 分发机制也一样. 所以, 提出了使用 LVS 和 F5 来
解决网络第四层的负载均衡.LVS是软件, 运行在操作系统内核态, 可对 TCP 请求或更高层级的网络协议进行转发, 性能远远高于 nginx,
单机的 LVS 可支持几十万个并发的请求转发.F5是一种负载均衡硬件, 与 LVS 提供类似的功能.
- DNS 轮询实现机房之间的负载均衡. 随着用户的不断增加, 单机 LVS 也会成为一种瓶颈, 此时根据用户
所在地区和服务器机房距离等信息, 利用 DNS 服务器轮询策略, 自动选择最好的入口 IP 给与请求用户.
例如: 当用户访问https://www.taobao.com时, DNS 服务器会使用轮询策略或其他策略, 来选择某个 IP 供
用户访问.
这个方法在提供 DNS 服务的公司会提供此类 VIP 服务.
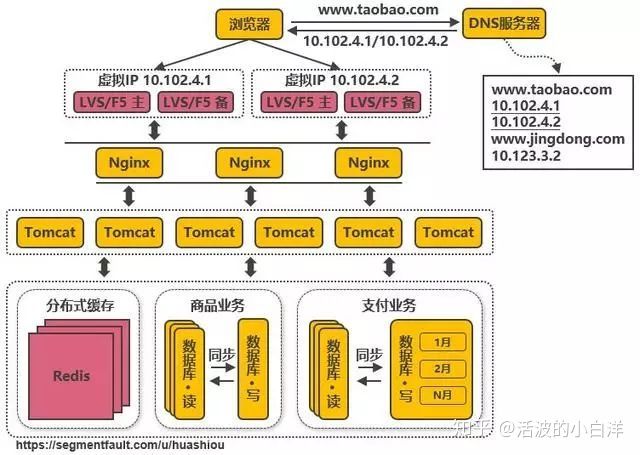
- NoSQL 数据库和搜索引擎等技术的引入, 替代传统的关系型数据库, 提高数据库的访问能力. 根据不同的
场景采取不同的解决方案:
- 海量文件存储: 分布式文件系统 HDFS 解决
- key value 类型的数据: 通过 HBase 和 Redis 等方案解决
- 全文检索场景: 通过搜索引擎如 ElasticSearch 解决
- 多维分析场景: 过 Kylin 或 Druid 等方案解决
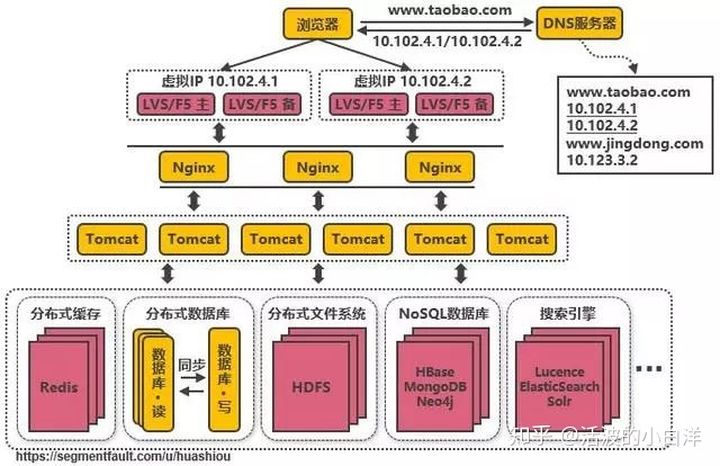
- 大应用拆分, 在业务层面更加精细化, 使单个应用的职责更清晰, 相互之间可以做到独立升级迭代.
业务之间的公共配置信息, 使用分布式配置中心 Zookeeper 来解决.
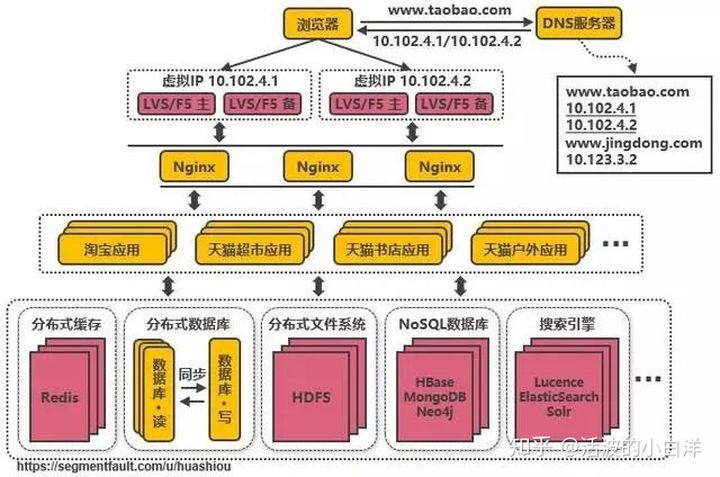
- 复用的功能抽离成微服务, 在大应用拆分为小应用的前提下, 仍旧存在一些公共业务模块, 例如支付
业务模块, 为了更好的迭代升级, 将这些公共业务独立出来, 以微服务的形式提供对外接口.
通过 Dubbo、SpringCloud 等框架实现服务治理,限流, 熔断,降级等功能.
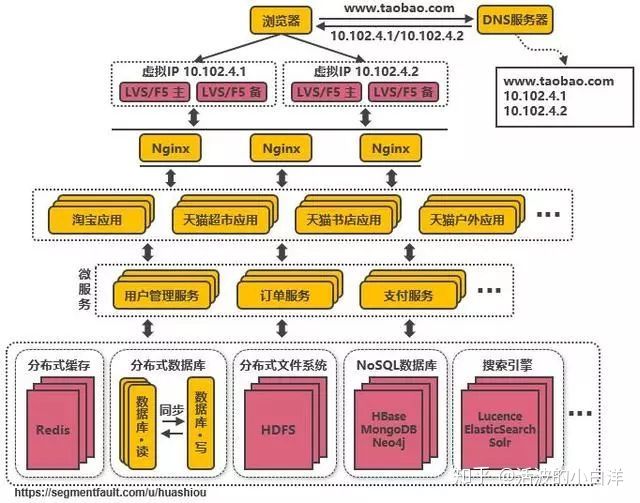
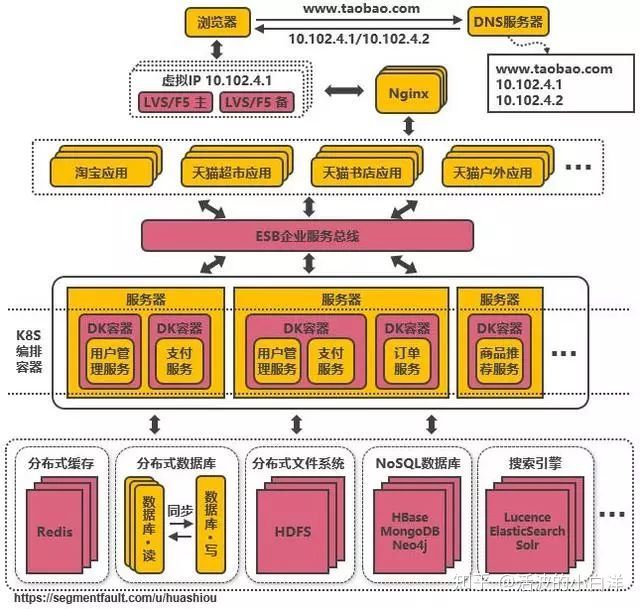
- 引入企业服务总线 ESB 屏蔽服务接口的访问差异, 通过 ESB 统一进行访问协议转换, 服务与服务之间也
通过 ESB 来相互调用, 降低系统的耦合度.SOA架构: 单个应用拆分为多个应用, 公共服务单独抽取出来来管理, 并使用企业消息总线来解除服务之
间耦合问题的架构.
微服务架构更多是指把系统里的公共服务抽取出来单独运维管理的思想.SOA 架构则是指一种拆分服务并使
服务接口访问变得统一的架构思想
- 引入容器化技术实现运行环境隔离与动态服务管理, 使用 K8S 实现服务的动态分发和镜像部署.
例如, 在大促的之前可以在现有的机器集群上划分出服务器来启动 Docker 镜像来增强服务的性能, 大促过后
就可以关闭镜像, 对机器上的其他服务不造成影响.
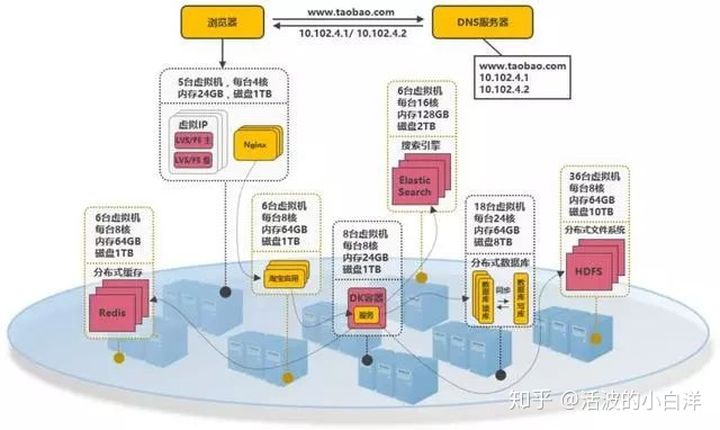
- 以云平台承载系统. 系统可部署到公有云上, 利用公有云的海量机器资源, 解决动态硬件资源的问题.
云平台: 把海量机器资源, 通过统一的资源管理, 抽象为一个资源整体, 之后按需动态申请硬件资源,
并且使用通用的操作系统, 常用的技术组件(技术栈).
例如, 在大促的时间段里, 在云平台中临时申请更多的资源, 结合 Docker 和K8S来快速部署服务, 在大促
之后释放资源, 真正做到按需付费.
上面所述的都是参考引用文章, 自己只是在做一个知识备份, 更多信息请看原文.
引用
参考:
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 狂想写作本!
 alipay
alipay



评论


