rsync和inotify实现文件同步
Rsync
介绍
rsync是一个为Linux/Unix系统做局部拷贝, 文件同步, 远程文件拷贝, 远程文件同步的命令, 从而实现数据备份或者镜像. 有人说, rsync实际上就是一个高级版的scp命令, 实际上在一定范围内, 这种说法是对的, 那么让我们提出疑问?
- rsync能够解决何种问题?
- rsync相比scp命令, 有什么优势? rsync是否不仅仅是scp命令那么简单?
- rsync的局限性在哪里?
软件开发过程中任何人都不能跳过需求分析, 一款应用必定是在继承传统功能的基础上解决新的问题, 那么让我们先看看scp命令的缺点:
- 占用大量带宽, 当然, 你可以先进行压缩再进行文件传输
- 全量拷贝, 速度慢, 占用带宽多, 无法增量备份
rsync能够解决上述提出的问题, 当然, 按照官网的介绍, rsync的主打功能就是增量备份.provides fast incremental file transfer., 通过特殊的算法实现差异同步上传, 常常用于实时性要求不高的分布式集群文件一致性问题, 分布式日志集中化问题, 文件镜像等.
相比scp命令, rsync提供了更加丰富的功能, 文件一致性同步在很多实时要求不高, 特别是中小型应用上能够非常好的解决问题,例如我们项目组就使用 rsync + inotify 来实现分布式爬虫中日志, 错误 HTML, 最终 PDF 文件等同步问题, 再基于以上基础在数据中心服务器上搭建 FTP 服务就能完美的将某一个提交引擎任务产生的所有错误文件, 最终结果文件直接呈现给开发者/运营人员. 简单框架如下: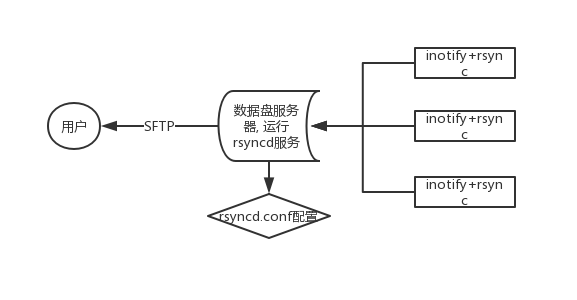
这是scp功能远远达不到的需求, 另外因为很多服务器都放在香港机房, 公司也没有购买专用的云 VPN 通道, 网络环境非常不好, 在准备使用logstash + ElasticSearch + Kibana之前没有很好的日志集中化工具, 就算搭建了这个环境, 但是因为 GFW 或者阿里云自身的原因, 可能这个框架并不能非常稳妥的运行, 除非将ELK完全搭建在香港环境, 这明显是不合逻辑的.
这里提到 GFW, 就不得不提醒一下, 不知道 GFW 是怎样的一种防御逻辑, 导致网络非常的不稳健, 经常无法从香港环境直接pull代码, 导致CI(Continue Integrate)根本无法进行, 最终只能通过fabric + scp来完成自动化部署任务. 另外, 偶尔会发生香港环境调用国内的HTTPS/HTTP 请求, 然后再 TCP/IP 层面被丢包弃置, 没有任何响应, 导致调用方一直保持 TCP 连接在Estashlib状态, 从而导致整个python进程卡主..
好了, 回到正题, 上面已经介绍了rsync的优点以及应用场景, 那么局限性呢?
- 无法在大型应用上使用, 例如日志集中化和分析, 最好还是使用成熟的框架, 例如 ELK
- 无法在实时性要求非常高的系统上使用
- 无法在存在大量文件(百万级)的基础上做增量, 其每次都要全盘扫描整个目录, 非常耗费资源
- 每次生成传输文件列表都需要做大量计算和校验, 这对 CPU 是一个很高的消耗
让我们举一个例子, 现在存在一个目录:Dir, 其下面有两个子目录subdir1, subdir2, 一个文件Readme.md, 其中每一个子目录都包含百万级数量文件, 如果此时更改了Readme.md文件, 那么就会发生: 全盘扫描整个Dir目录, 判断所有发生更改的文件, 这是非常耗费 CPU. 虽然通过一定的脚本, 配置inotify, 能够在底层目录文件发生变化的时候仅仅扫描发生变化的文件所在的目录, 这样减少了扫描的数量, 但是你无法避免某一个时刻Readme.md文件发生变动, 具体实现见 2.3 节的最小同步.
安装和配置
1 | # centos |
在启动rsyncd服务之前, 让我们先了解一下/etc/rsyncd.conf中各个选项的含义:
1 | uid = root |
其中各个字段说明(参考官网):
1 | uid = 守护进程运行时用户全局配置 |
注意, 关于权限问题有几天需要注意:
- 确保服务器这边的 UID/GID 有权限对模块中的path进行写入/读取操作
- 确保客户端这边执行rsync的用户有权限读取信息
- 确保客户端能够通过 UID 指定的用户连接服务器, 不然会出现错误
- 确保所有的密码文件权限都是:600, 不管是客户端还是服务器, 这个很重要
密码文件的格式有两种: 服务器和客户端, 其中服务器的密码格式如下:
1 | username:password |
其中username必须同auth users保持一致, 这个值与客户端的认证用户名保持一致, password会客户端的认证密码. 客户端密码格式如下:
1 | password |
这个文件在客户端中指定.
客户端
在已经启动服务器进行监听的前提下, 任何一个在/etc/rsync.conf中指定的模块认证通过的机器都能通过rsync命令来和服务器进行文件的同步工作: 文件的推送, 文件的拉取. 当然, 正如前文提到的, 客户端所指定的密码文件权限页必须为600, 同时认证用户名和密码必须同服务器配置文件中的某一个模块配置保持一致.
在完成基本的客户端配置之后, 此时rsync就立刻变成一个升级版的(scp, cp, tar), 具有高安全性, 备份迅速, 增量备份, 但是注意此时同步文件仍然需要人为手动触发, 这不是一个事件触发机制, 而是一个主动发起的同步机制, 你可以使用crontab来完成一定时间间隔的文件增量备份操作. 好了, 很多人肯定想到问题了:
- 手动触发或者通过crontab触发如何控制时间间隔?如何做到实时性?如果调用太快, 但是大部分时候没有增量数据时是否浪费?
- 对于一个庞大的文件系统, 根据rsync的原理, 在目录越顶层发生变动时, 牵涉到整个庞大社会的文件同步操作, 浪费性能
这时候就有了inotify + rsync配合机制, 当然这种机制实际上也解决不了顶层目录的文件变动导致的庞大数据备份操作, 当时相比而言性能总归有一定的提升, 这个见下一章的说明. 现在, 让我们先了解一下rsync的同步命令以及常见的参数说明. rsync总共有 6 中工作方式, 以实现和服务器的增量同步操作:
1 | # 拷贝本地文件, 就相当于cp命令的优化版 |
例子说明如下:
1 | # a 本地主机: 压缩文件 |
其他参数说明, 这里仅仅列出部分参数说明:
1 | -p --progress 显示传输进度 |
规则
对于规则我们肯定有很多疑问: 规则是如何生效的? 它的工作原理是怎样的? 规则的配置是怎么样的? 在了解这些问题之前让我们先了解一下rsync命令生效的那一刻所做的工作:
- rsync开始扫描给定的文件或目录, 排序之后生成一个拷贝树(copy tree)
- rsync在扫描完成之后会将生效或待传输的文件或目录记录到文件列表中
- rsync开始将文件传输给接收端
其中规则的处理或过滤就在copy tree生成的那个阶段, 规则在整个流程的最前方就开始生效, 通过exclude规则, include规则以及其他这里未介绍的规则, 生成一个显式的文件列表. 那么如何配置一个exclude规则, include规则呢? 在配置规则的时候我们应该怎么进行调试呢?
- 使用-i, -r, -n来进行调试, 获取生效的文件列表, 从输出中获取绝对路径/相对路径
- 绝对路径和相对路径决定了规则文件编写时的路径信息, 这个在后面的例子出说明
- 使用正则基本语法来进行匹配操作,例子见下面
通过-nr -i来调试获取绝对/相对路径信息, 下面这段说明和测试是参考他人的例子:
1 | # 显示了传输文件的路径"a/*",也就是说包括了目录a,且是相对路径的.所以要写规则时,需要加上这个a路径 |
讲解完如何确定相对路径和绝对路径信息之后了解一些复杂的正则例子:
1 | 需求: 同步/tmp/src/文件和目录, 排除/tmp/src/mail/2014/, /tmp/src/mail/2015/cache/目录 |
另外, 相比--exclude正则配置, --exclude-from指定的文件更加直观, 繁琐, 该文件详细指定了黑名单, 会将所有待忽略的文件一个个
的列出来.
Inotify
介绍
在上面 1.1 节的介绍中我们提到rsync的缺点以及inotify + rsync的配合使用, 那么:
- inotify是什么?
- inotify为何能够解决rsync问题?
- inotify和rsync是如何配合使用的?
- 是否有相关的例子说明呢?
inotify是一个细粒度(到单一文件级别), 异步的文件系统事件监控机制, 任何文件的变动都会触发inotify的事件通知. 利用事件通知机制, 让inotify可以做到实时的文件变动通知, 并以细粒度方式获取变动的文件, 以最小权限影响范围告知rsync进行极小范围的文件变动, 实现实时性的文件增量同步.
那么事件是什么? 做过linux开发的同学可能比较了解事件监听机制, 里面包括很多事件通知类型, 比如文件的修改, 文件的删除, 文件的新增等等, 目前inotify的事件类型如下:
- IN_ACCESS: 文件被访问.
- IN_MODIFY: 文件被write.
- IN_ATTRIB: 文件属性被修改,如chmod,chown等.
- IN_CLOSE_WRITE: 可写文件被close.
- IN_CLOSE_NOWRITE: 不可写文件被close.
- IN_OPEN: 文件被open.
- IN_MOVED_FROM: 文件被移出被监控目录,如mv.
- IN_MOVED_TO: 文件被移入被监控目录,如mv,cp.
- IN_CREATE: 文件/文件夹被创建.
- IN_DELETE: 文件/文件夹被删除,如rm.
- IN_DELETE_SELF: 自删除,即一个可执行文件在执行时删除自己.
- IN_MOVE_SELF: 自移动,即一个可执行文件在执行时移动自己.
- IN_UNMOUNT: 宿主文件系统被umount.
- IN_CLOSE: 文件被关闭,等同于(IN_CLOSE_WRITE|IN_CLOSE_NOWRITE).
- IN_MOVE: 文件被移动,等同于(IN_MOVED_FROM|IN_MOVED_TO).
利用上述的事件通知机制以及一定的判断逻辑, inotify + rsync能在一定范围内做到较低功耗的实时同步策略, 具体例子见2.3 节介绍.
安装和参数
1 | yum install inotify-tools |
inotify的参数相比rsync稍微简单一点, 下面讲解一下日常经常使用的 inotify 参数:
1 | -m 表示始终保持事件监听状态 |
最小同步
让我们考虑如下的目录结构:
1 | Dir |
根据上面的说明, 通过inotify来监听变动文件, 最后使用rsync来进行文件的增量同步, 但是对于庞大的文件系统, 比如假设test2目录下面有非常多的文件, 并且每个文件都非常大, 那么如果a.log文件发生变动, 那么会发生什么呢? 网络上的很多例子会直接进行整个Dir目录的同步操作, 这会触发所有文件的扫描以便决定是否进行增量备份, 这是非常耗性能的, 那么我们应该如何避免此类情况呢?
- 根据最小权限原则, 将影响的文件范围尽可能的控制到最小, 即仅仅同步test1目录
- 利用rsync指定同步目录
根据上面的思路, 我们通过inotify获取发生变动的文件INO_FILE, 获取该文件的上层目录, 然后仅仅开始同步该目录, 这样就能以最小的功耗上线我们的目的, 整个例子如下:
1 | # 根据不同的事件来决定不同的同步策略 |
那么上面的解决方式是否有其他隐患呢? 一般来说, 只要上面的应用每次都正确的运行, 那么就能实现整个庞大文件系统的增量备份, 但是万一某一次小的同步出现问题呢, 然后此次同步相关的文件在一个非常非常小的角落中, 然后后续的所有同步都没有将该文件包含进去, 那么就会出现如下的奇妙现象: 这个小文件一直没有同步成功, 虽然这个几率非常小. 为了解决这个问题, 我们仍然需要一个crontab来定时的对整个庞大文件系统进行全局扫描和增量同步, 实现方式如下:
1 | rsync_all() |
最后编写crontab来定时的调用rsync_all, 使用nohup来启动一个后台进程, 调用listen以实时监控待同步的文件目录, 最终
完成一个较为稳妥的零散文件, 日志集中化, 实时增量同步框架.
配置实例
规则
a) 权限错误
原因: 确保Client和Server都是同样一个用户权限, 例如Client使用root来启动脚本, Server使用root来启动rsyncd服务, 否则会报权限错误. 具体例子:
1 | rsync: chgrp "test1" (in cn-app-server2) failed: Operation not permitted (1) |
参考
 alipay
alipay








