算法:交换排序
站内链接:
- 算法(1)-检索-简介
- 算法(2)-检索-散列检索
- 算法(3)-检索-顺序检索
- 算法(4)-检索-树检索
- 算法(5)-排序-简介
- 算法(6)-排序-分配排序
- 算法(7)-排序-插入排序
- 算法(8)-排序-选择排序
- 算法(9)-排序-交换排序
- 算法(10)-排序-外排序
Introduction
根据排序算法中说明,可以了解, 基于交换的排序目前有两大类: bubble-sort, quick-sort. 所有交换排序, 受方法本身的限制, 最低的时间复杂度为 O(nlogn). 其中基于交换的排序, 都是在原有空间基础上, 进行两个数值的比较和交换工作, 所有的交换排序步骤:
- 比较两个值, 判断大小
- 如果发现逆置, 则交换两个元素
- 不断地进行上述的操作
维基百科: 冒泡排序, 快速排序, 冒泡排序和快速排序的动画演示.
冒泡排序
Analysis
本质上,一种比较类-非线性时间-交换类-排序. 冒泡排序是一种简单的排序算法, 重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来, 走访数列的工作是重复地进行直到没有再需要交换.这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端.
1 | 我比你大,我们两得换换了;(仅仅和相邻元素进行对比) |
性能:O(n*n)
Example
1 | def bubbleSort(list1): |
快速排序
Analysis
基于分治法, 可以将 Quicksort/Partition-exchange sort 分为如下三步:
- 在数据集中, 选择一个元素作为基准 pivot
- 所有小于 pivot 的元素, 都移动到基准的左边, 大于 pivot 的元素移动到基准的右边, 其中 pivot 所在的位置就是最终的位置, 称为 partition 操作
- 对 pivot 左右两边的子集, 重复使用分治法, 直到所有子集都是剩下一个元素为止.
说明:
- 本质上,比较类-非线性时间-交换类-二分法思维(分而治之)-排序
- 大哥,我们两一起将 SB 归为 SB,NB 归为 NB,标准以我为参考(k = A[i])
- 大哥,你先走,我等下将 NB 的人替换你哪里 SB 的人(交换 A 小于 k,B 小于 k 时的两值)
- 大哥,革命会师之日就是你我相见之时(表示一次基准二分结束)
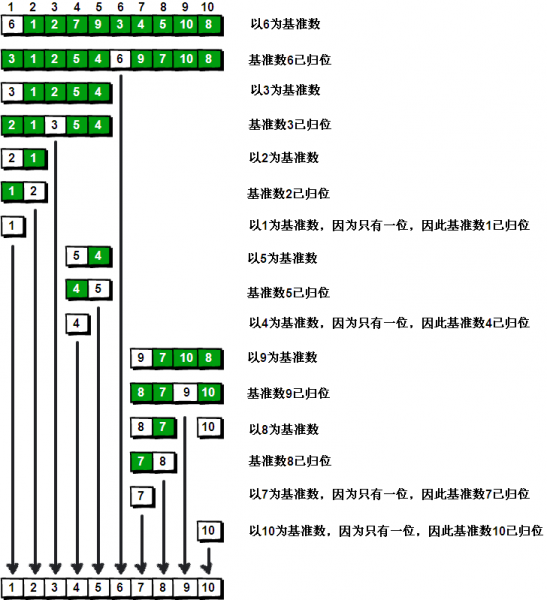
性能分析
时间复杂度: O(nlogn), 最坏情况 1.4*O(nlogn), 该值可见维基百科说明.
空间复杂度: 最好情况-O(nlogn), 最坏情况-O(n^2 logn)
快速排序是二叉查找树的一个优化版本, 根据快速排序来组织这些数据项到一个隐含的树中, 实际上大部分的分治法都会产生一棵隐含的树结构.
- 快速排序与堆排序: 两者性能类似, 堆排序稍慢于快速排序, 但是最坏情况 O(nlogn)
- 快速排序与归并排序: 最坏情况 O(nlogn), 归并排序是一个稳定的排序算法, 可以在外排序中使用
Example
1 | def qsort(list1, left, right): |
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 狂想写作本!
 alipay
alipay
相关推荐





评论


